ARTICLE SIGNAL
AI生成内容检测“潜规则”?开源模型助你降低AIGC率,重塑学术写作新范式
深度解读降低AIGC率的开源模型,解析其背后的SFT与DPO技术,探讨AI时代下学术诚信与教育评估的未来。
type
status
date
slug
summary
tags
category
icon
password
网址
随着人工智能生成内容(AIGC)技术的飞速发展,高校和学术界正面临前所未有的挑战,尤其是关于学术论文的原创性检测。近期,一篇关于“我们开源了一个可以降低AIGC率的模型”的文章引起了广泛关注。本文将深入解读这一技术突破,分析其背后的原理,并在此基础上进行扩展,探讨AI时代下学术诚信、教育评估以及技术发展的未来方向。
AIGC率检测的痛点与挑战
毕业季的到来,使得“AI率”成为了许多学生和导师头疼的问题。知网、维普等主流学术查重系统纷纷引入AI检测功能,许多学校要求AI生成内容的比例压制在30%以下。然而,现有的AI检测系统往往存在“黑箱”操作:其训练数据、特征设计、阈值策略均不公开,使得研究者难以理解其工作原理,更遑论针对性地去优化或规避。传统的PPO(Proximal Policy Optimization)或GRPO(Generalized Proximal Policy Optimization)等强化学习方法,在缺乏可量化的“奖励”(reward)信号时,难以直接应用于对抗这些检测器。
从绕过到对齐:模型训练的新思路
面对严峻的检测形势,研究者并未选择直接攻击检测器,而是转换思路:能否训练一个模型,使其生成的文本在保持学术规范和信息准确性的前提下,显著降低被判定为AI生成内容的概率?这背后是一种从“绕过”到“对齐”的理念转变——让AI的输出更接近人类的自然表达方式,而非简单地生成“AI味”十足的文本。
探索与试错:两条捷径的局限性
在正式训练模型之前,研究者尝试了两种更为省力的路径:
- 利用现成Prompt或Skill进行改写:虽然GitHub上存在一些英文的“humanizer”项目,但中文方向的成熟工具相对匮乏。一些中文项目采用传统NLP的规则替换方式,检测和改写手段都较为粗糙,难以满足学术场景的精细化要求。
- 更换冷门模型:理论上,使用统计分布差异极大的冷门模型,可能天然规避主流检测器。然而,这类模型往往对中文支持不足,效果不佳,且未经针对性微调,其底层分布与主流模型差异也有限,这条路最终被证明不可行。
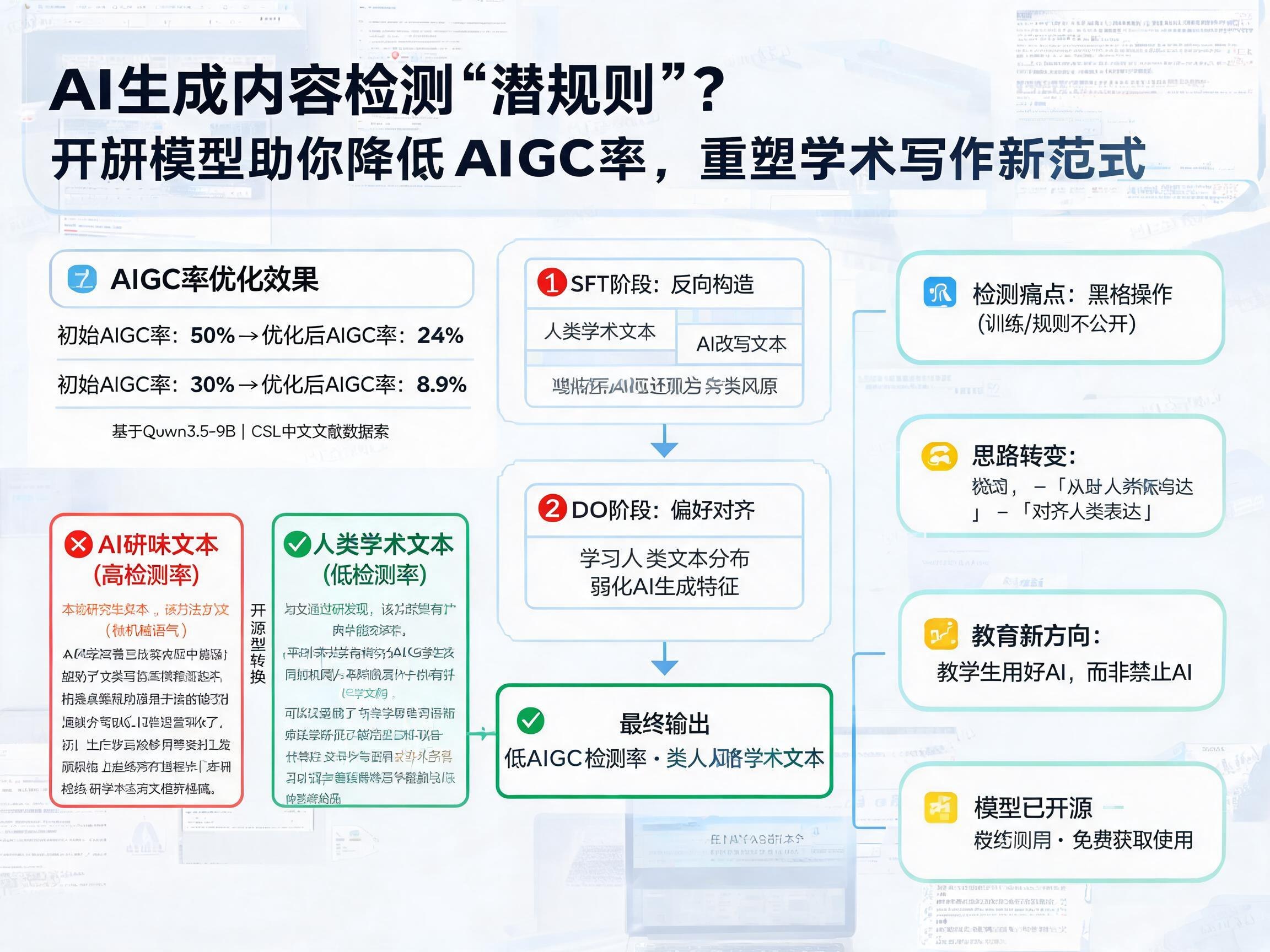
SFT阶段:反向构造的初步尝试
当捷径被证明不可行后,研究者回归到核心的训练环节。第一步是监督微调(Supervised Fine-Tuning, SFT)。其核心思路是“反向构造”:收集一批人类写的文本,先用AI工具将其改写成“AI味”很重的版本,然后训练模型学会将AI文本还原成人类风格。
关键在于原始文本的选择。初期尝试使用互联网网页数据,但存在数据清洗繁琐和模型过于口语化的问题,不适用于学术场景。最终,研究者选用了 CSL(Chinese Scientific Literature)数据集,该数据集包含大量中文论文摘要,其语言风格与正文段落差异不大,能提供相对高质量的学术文本基础。
通过对约18000条“AI改写摘要 -> 原始摘要”的样本进行训练,基于Qwen3.5-9B模型,得到了一个初步可用的版本。该模型能保留学术术语,但存在两个主要问题:一是改写程度不够,依然容易被检测系统识别;二是通用性差,在学术场景下过于保守,在日常场景下又显得过于文绉绉。
DPO阶段:迈向“人类分布对齐”的关键一步
为了进一步提升模型效果,研究者引入了直接偏好优化(Direct Preference Optimization, DPO)。DPO是一种无需显式奖励模型即可进行强化学习的方法,特别适合在缺乏精确奖励信号的情况下,让模型学习人类的偏好。
DPO阶段的第一个关键错误在于数据构造。初期沿用了SFT的思路,将人类原文视为“Chosen”(优选),AI改写版本视为“Rejected”(拒绝)。然而,AI改写后的文本往往更书面化、严谨,相比之下人类原文反而更显口语化。模型学到的信号变成了“越口语化越好”,而不是“越接近人类分布越好”。
修正后的DPO数据构造采用了双向策略:一方面,保留2000条“formal-rejected”样本,AI改写维持正式书面语气;另一方面,构造2000条“casual-rejected”样本,AI改写加入更多口语化、灵活的变体。这种方式使模型真正学会了“人类文本”的感觉,不再简单区分口语化或书面化,而是学习一种更自然的、更像人的表达风格。
自博弈与信号纯度的教训
在DPO基础上,研究者尝试利用自博弈(Self-play)进一步提升模型性能。自博弈是指让模型自身生成文本,然后通过某种机制(如另一个模型或某种评估标准)来评估其质量,并据此进行优化。
自博弈阶段的第二个错误是混杂了自博弈数据和部分口语化rejected数据。本意是为模型增加“围栏”,防止其跑偏。但自博弈产生的学习信号本身较弱,与口语化rejected数据的强区分信号混合后,导致训练过程剧烈抖动,梯度暴涨。
最终的成功在于信号的纯化。研究者果断放弃了混杂版本,去掉所有口语化数据,确保学习信号的单一。同时,将学习率调低一半,以更慢的速度防止模型跑偏,并将自博弈数据扩展到2000条。
此次训练完成后,模型达到了一个接近可用的状态。在实际测试中,一篇AI率50%的论文改写后降至24%,另一篇从30%降至8.9%。人工抽查也证实了语义和事实信息的保留基本完整。
DPO模型在通用性上的优势
一个有趣的现象是,SFT模型在处理日常文本时,倾向于将其改写成文言文式的表达;而DPO Stage-2版本,即便训练数据主要来自学术论文,但在日常场景下也展现出极高的可用性,表达自然。这表明DPO阶段学到的“人类分布对齐”能力,比SFT阶段更深层、更具泛化性,能够从学术文本中提炼出通用的、更像人的语言特征。
AI时代下的教育反思
此次开源模型的研究,不仅是技术上的进步,更引发了深刻的思考:
- 检测的本质:AI检测系统往往拦住了那些“懒得折腾”的人,而真正有决心和能力的人,往往能找到解决之道。随着类似工具的普及,反检测的产业将愈发成熟。
- 教育的重心:在AI工具已无处不在的今天,教育系统是否应该将精力从“检测学生是否使用AI”转移到“教学生如何用好AI”?
- 未来的评估体系:如何设计一套新的评估体系,能够衡量学生在AI辅助下学习到的真实知识和解决问题的能力,这才是高校在AI时代真正值得投入的方向。
正如作者所言,AI时代的到来,要求我们重新审视教育的本质和目标,拥抱技术,引导学生与AI协同发展,而非一味地将其视为洪水猛兽。
该模型及其合成数据已开源,为研究者和学习者提供了宝贵的资源,期待未来能有更多类似的研究,共同推动AI技术在教育领域的健康发展。
Loading...