ARTICLE SIGNAL
英伟达世界模型训练提速400%:RLinf框架如何实现AI训练的“一周顶一个月”
深度解读英伟达DreamZero世界模型训练速度飙升400%的秘密。RLinf框架通过算子优化、算存联合调优及IO提速,大幅降低具身智能模型训练成本,加速AGI进程。
type
status
date
slug
summary
tags
category
icon
password
网址
在人工智能(AI)飞速发展的今天,构建能够理解并预测物理世界的“世界模型”被认为是迈向通用人工智能(AGI)的关键一步。英伟达近期发布的World Action Model (WAM) DreamZero,凭借其在视频数据中学习物理规律的能力,在具身智能领域引起了广泛关注。然而,如其名所示,强大的模型往往伴随着巨大的训练成本。一篇来自aitntnews.com的文章《一个月的活一周干完!英伟达世界模型训练速度飙升400%》揭示了这一挑战,并介绍了RLinf框架如何以前所未有的效率解决了这一难题。本文将深入解读这一技术突破,并探讨其对AI发展的重要意义。
世界模型:AGI的“物理引擎”
世界模型的核心在于让AI具备对物理世界的深刻理解和预测能力。与传统模型不同,DreamZero等WAM模型以视频作为核心学习材料,能够从海量互联网视频中提炼出通用的物理规律。这种范式革新使其不再需要海量的单一动作演示,而是能通过多样化数据学习世界运行的本质,从而在未知环境中依然表现出色。在RoboArena和MolmoSpaces等机器人基准测试中,DreamZero展现出了超越现有最优VLA模型的性能,在任务成功率、泛化性等方面实现了显著提升,为多机型协同和低成本迭代提供了可能。
高昂的训练成本:AGI之路上的“拦路虎”
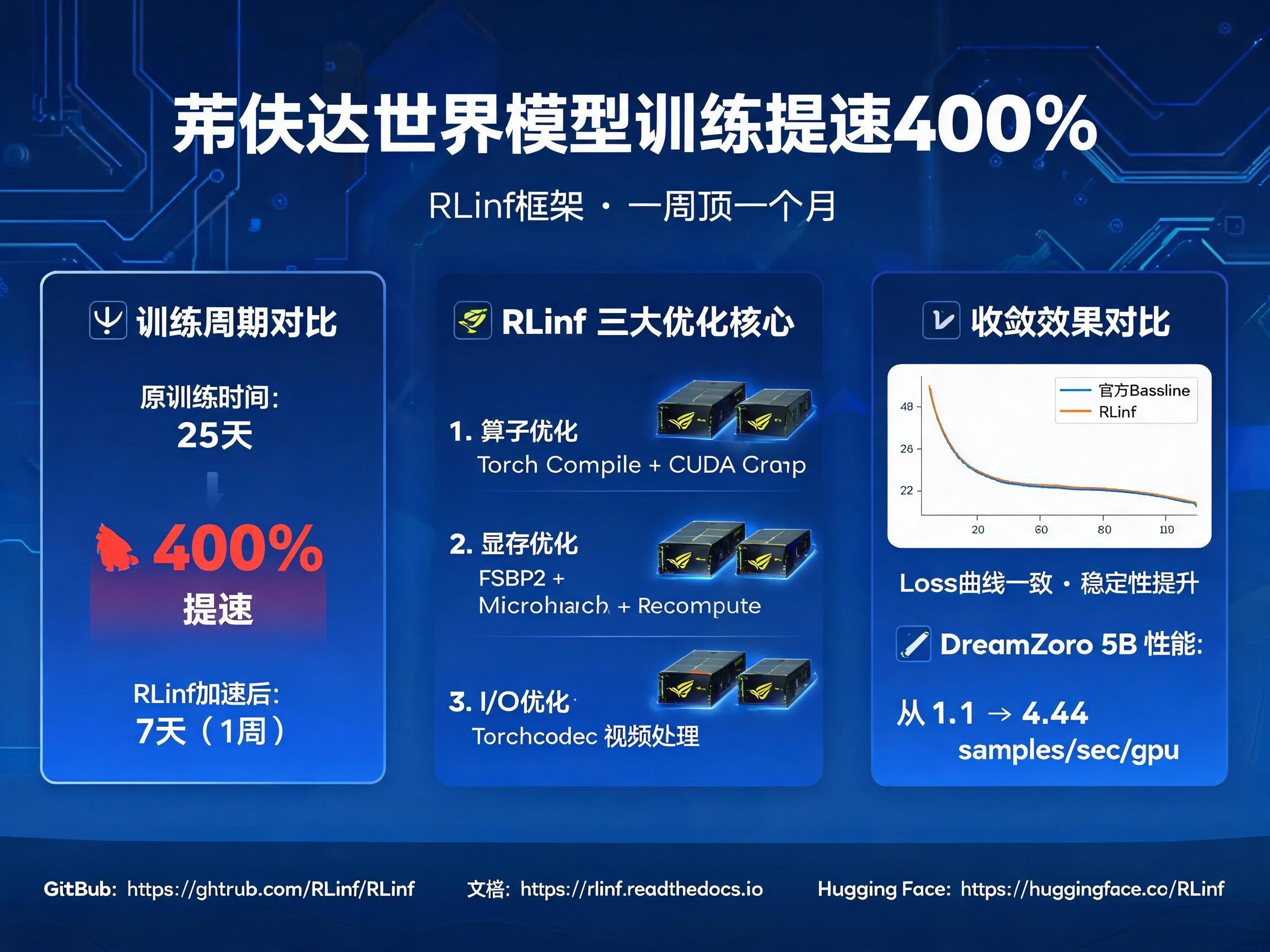
尽管DreamZero在性能上表现卓越,但其训练过程却面临巨大的算力和显存挑战。以Diffusion架构为主体的WAM模型,其训练耗时和计算资源需求极为可观。根据抓取文章信息,官方开源的DreamZero训练代码,使用8张H100 GPU训练数据,完整周期长达25天。如此高昂的训练成本和耗时,无疑成为了行业内大规模复现和快速迭代的主要门槛。
RLinf框架:系统级重构,训练速度飙升400%
为了打破性能瓶颈,加速前沿研究的落地,无问芯穹与清华大学等联合推出的RLinf大规模强化学习框架,为DreamZero的训练提供了深度支持。RLinf不仅仅是对DreamZero官方训练脚本的简单适配,更是对其训练管线进行了系统级的深度重构与加速。通过一系列底层优化,RLinf成功实现了近4倍的训练吞吐量提升,这意味着原本需要一个月才能完成的实验,现在仅需一周即可搞定。
揭秘RLinf的“加速引擎”:三大优化维度
RLinf框架是如何实现如此惊人的训练加速的呢?其核心优化思路集中在以下三个关键维度:
1. 极致的算子与计算图优化:Torch Compile + CUDA Graph
Python层面的算子和调度开销常常是限制GPU峰值性能的“隐形杀手”。RLinf深度融合了
torch.compile和CUDA Graph技术,解决了这一痛点。- Torch Compile:通过底层的编译优化,对算子进行深度融合(Kernel Fusion),特别是对Diffusion架构中可能存在的低效算子(如WanRMSNorm, adaLN-zero等)进行了优化。
- CUDA Graph:将计算图固化,有效消除了GPU launch的CPU调度瓶颈。在DreamZero训练中,对于CausalWanSelfAttention等kernel launch密集的环节,CUDA Graph能够显著提升效率。
这项优化使得DreamZero 5B和14B模型在不改变原有配置下,分别获得了50%和34%的训练加速,将单步耗时从1.8s/step降至1.2s/step(5B模型),从9s/step降至6.7s/step(14B模型)。
2. 计算与显存的联合优化:解锁全方位性能调优
为了应对大模型训练中必不可少的性能调优需求,RLinf在计算与显存优化上进行了深入的工程实践:
- 稳定适配FSDP2:RLinf迁移到了PyTorch官方推出的最新ZeRO实现——FSDP2。这解决了此前DreamZero官方代码中DeepSpeed方案存在的与VAE模块兼容性冲突问题,以及反向传播阶段CPU侧的开销瓶颈。用户可以根据显存配置灵活切换分片策略。
- 灵活的Microbatch Size (mbs)设置:RLinf彻底解决了mbs > 1时与FSDP2、Recompute特性共存的不兼容问题,并确保了Image Encoder能够高效地进行Batch处理。这使得用户可以根据硬件资源进行精细化参数调优,在显存占用与执行效率之间达到最佳平衡。例如,在5B模型训练中,mbs从1提升到2,单步耗时几乎不变,但吞吐量增加了85%。
- Recompute机制与加速算子的深度协同:通过底层的工程优化,RLinf实现了Recompute(激活重计算)与CUDA Graph、FSDP2的稳定解耦与协同。在显存受限环境下,Recompute以微小的计算耗时换取显著的显存空间释放,支持更大规模的并行任务。在5B模型训练中,开启Recompute后,mbs可从2大幅提升至32,单卡吞吐量提升158%(从1.7 samples/sec/gpu提升至4.4 samples/sec/gpu)。
通过FSDP2、mbs和Recompute的全局参数调优,RLinf在5B模型训练上,将训练性能在算子优化基础上进一步提升了266%,达到了4.4 samples/sec/gpu。
3. 突破I/O吞吐瓶颈:高效视频数据处理管线
随着计算密度的提升,数据加载效率逐渐成为新的瓶颈。在DreamZero训练中,视频解码和预处理过程消耗大量CPU资源。RLinf团队通过性能Benchmark,选择了CPU占用更稳定的Torchcodec库,而非仅在解码速度上占优的PyAV。这一优化显著缩短了单个视频的解码时间近400ms,为后续GPU计算潜力的压榨提供了充足的数据“弹药”。
性能实测:从“能跑通”到“极致高效”
RLinf框架的优化效果在实际测试中得到了充分验证。
- DreamZero-14B模型:RLinf相比原生DeepSpeed方案实现了2.7倍的加速,即便对比未经优化的FSDP2,吞吐量也进一步提升了35%。
- DreamZero-5B模型:RLinf的训练吞吐量从官方代码的1.1 samples/sec/gpu飙升至4.44 samples/sec/gpu,相比受限的FSDP2 Base版本,实现了惊人的5.84倍性能飞跃。
训练收敛效果:速度与精度的双重保障
RLinf框架在追求速度的同时,并未牺牲模型的训练精度。通过对DreamZero 5B模型在LIBERO数据集上的Loss曲线对比,RLinf(橙线)与官方Baseline(蓝线)呈现一致的收敛趋势。值得注意的是,RLinf通过底层重构,实现了Episode内部的Step粒度随机采样,有效平滑了训练过程中的噪声,提升了梯度更新的稳定性,使得Loss曲线更为平滑。
在Spatial Benchmark的端到端测评中,RLinf训练的模型在18k Step时达到了96.68%的最优成功率,充分证明了其在大幅缩短训练耗时的同时,完全保持了模型原有的训练效果与收敛质量。
总结:让世界模型迭代跑在“快车道”
RLinf框架对DreamZero世界的深度支持,是一次系统级的重构,而非简单的参数微调。从算子融合到I/O调优,从并行策略的纠偏到mbs自由度的释放,RLinf实现了近4倍的吞吐提升,将AI研究人员的实验周期从一个月缩短至一周。这不仅是一个强大的工具库,更是具身智能领域高效迭代的“加速器”。
想要亲身感受RLinf带来的4倍提速效能,加速您的具身智能研究,欢迎访问RLinf的GitHub仓库,开启您的DreamZero世界模型训练加速之旅。
代码链接:https://github.com/RLinf/RLinf
Hugging Face链接:https://huggingface.co/RLinf
使用文档链接:https://rlinf.readthedocs.io/zh-cn/latest/rstsource/examples/embodied/sftdreamzero.html
Loading...