ARTICLE SIGNAL
深度解析Bengio新模型GRAM:并行轨迹如何重塑大模型递归推理?
探索图灵奖得主Yoshua Bengio团队推出的GRAM模型,揭秘生成式递归推理如何通过并行采样碾压传统串行推理。本文深入分析GRAM的层次化架构、随机引导机制及双轴扩展策略,助你掌握前沿AI资讯与大模型技术趋势。
type
status
date
slug
summary
tags
category
icon
password
网址
引言:大模型推理的新范式
在人工智能领域,如何提升大模型的推理效率与质量始终是核心命题。当前主流的推理模型,如采用链式思维(CoT)的模型,往往依赖于生成大量的中间token。然而,这种“想得越多、写得越多”的模式带来了显著的延迟和计算成本。近期,图灵奖得主杨立昆(Yann LeCun)指出,自回归生成或许并非通向通用人工智能(AGI)的终极路径。
紧随其后,另一位图灵奖得主Yoshua Bengio及其团队发布了重磅论文,提出了GRAM(Generative Recursive reAsoning Models,生成式递归推理模型)。这一模型打破了传统确定性递归推理的限制,引入了概率性的多轨迹计算。本文将深入解读这一技术突破,探讨其如何通过并行化方案实现对串行推理的“碾压”。
从确定性到概率性:打破递归推理的瓶颈
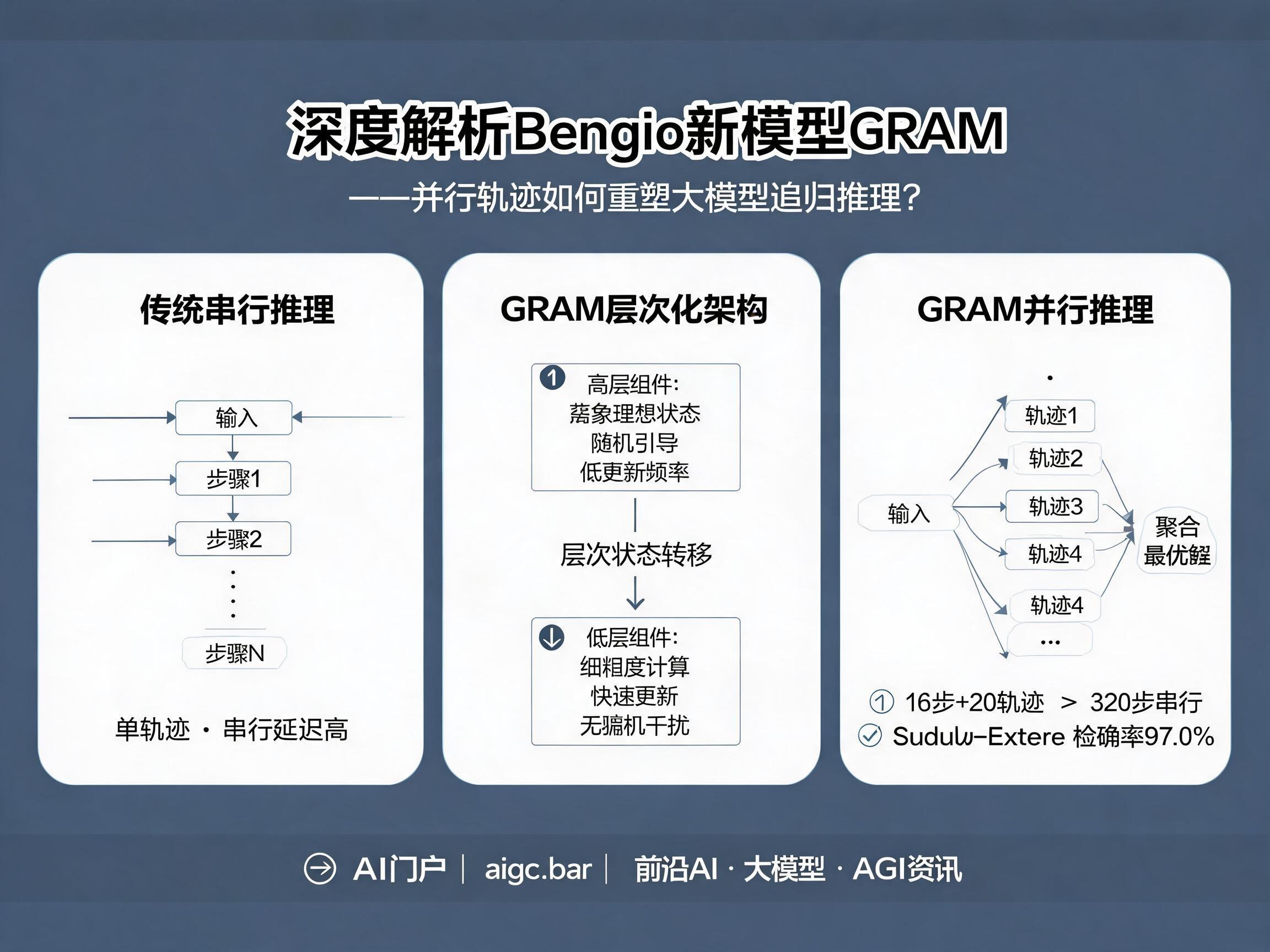
传统的递归推理模型(RRMs)虽然能通过共享参数的转移函数在潜在空间进行迭代,但它们大多是确定性的。这意味着对于同一个输入,模型只能沿着一条固定的路径前进。当面对复杂的约束满足问题(如数独或N皇后问题)时,这种单一路径极易陷入局部最优。
GRAM的核心创新在于将递归推理过程转化为一个潜变量生成过程。它在每一步递归中引入了可学习的随机性。具体而言,模型不仅计算一个确定性的“提议更新”,还会采样一个状态相关的“随机引导信号”。这种设计让模型在保持精炼能力的同时,能够捕获不确定性,并支持对解空间进行全方位的多路径探索。
层次化架构:抽象与精细的完美平衡
为了确保推理的高效性,GRAM采用了独特的层次化潜在状态结构,将状态分为高层组件和低层组件:
- 高层组件:承载抽象的推理状态,更新频率较低,随机性仅注入这一层,用于引导整体推理轨迹的方向。
- 低层组件:负责细粒度的中间计算,在每次转移内部进行多次快速更新。
这种架构确保了随机引导作用于更宏观的推理层面,而不会干扰底层精细的计算逻辑。这种“粗中有细”的设计,使得模型在复杂逻辑推演中表现得更加稳健。
双轴扩展策略:深度与宽度的协同
GRAM最令人兴奋的贡献之一是提出了推理时计算的“双轴扩展”策略,这直接改变了我们对模型计算预算分配的认知:
- 深度扩展(串行):通过增加递归步数来深化推理。
- 宽度扩展(并行):通过采样多条独立的推理轨迹,同时探索多个潜在解。
实验数据显示,GRAM在仅使用16步递归结合20条并行采样的情况下,其准确率就超越了传统模型在320步纯串行递归下的表现。这意味着,并行采样可以绕过深度扩展带来的延迟瓶颈。在相同的壁钟时间内,通过增加计算的“宽度”,模型能够覆盖更大的解空间,从而更高效地找到最优解。
实验验证:在复杂任务中的卓越表现
在多项严苛的基准测试中,GRAM展现出了统治级的性能。在Sudoku-Extreme(极难数独)任务中,GRAM达到了97.0%的准确率,远超TRM和HRM等确定性基线模型。
在处理N-Queens(N皇后问题)等具有多解性质的任务时,GRAM的优势更加明显。传统的确定性模型往往只能找到一个解,而GRAM凭借其概率特性,能够实现极高的解空间覆盖率。同时,在ARC-AGI这类抽象推理挑战中,GRAM也一致性地超越了所有确定性递归模型,证明了其在处理未知逻辑规律方面的强大潜力。
总结与展望:迈向更高效的AGI
GRAM的出现,确立了“概率多轨迹递归”作为未来推理架构的重要方向。它告诉我们,一个真正智能的系统不仅需要思考得“深”,更需要思考得“广”。通过在潜在空间中引入随机性与学习引导,GRAM成功地将生成式模型的灵活性与递归模型的严谨性结合在了一起。
对于关注AI资讯和大模型发展的开发者与研究者来说,GRAM提供了一个清晰的信号:推理的未来在于潜在空间的概率探索。随着这类技术的成熟,我们有望看到更低延迟、更高智能的AI应用落地。
了解更多前沿AI新闻、人工智能技术解读及Prompt优化技巧,请持续关注 AI门户。在AGI的征途中,掌握核心算法逻辑将是实现AI变现与技术突破的关键。
Loading...