.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
Claude 通关率不足 4%:SaaS-Bench 揭示 AI Agent 「全自动办公」的严峻现实
type
status
date
slug
summary
tags
category
icon
password
网址
AI Agent 的「全自动办公」幻想破灭:SaaS-Bench 带来的冷峻现实
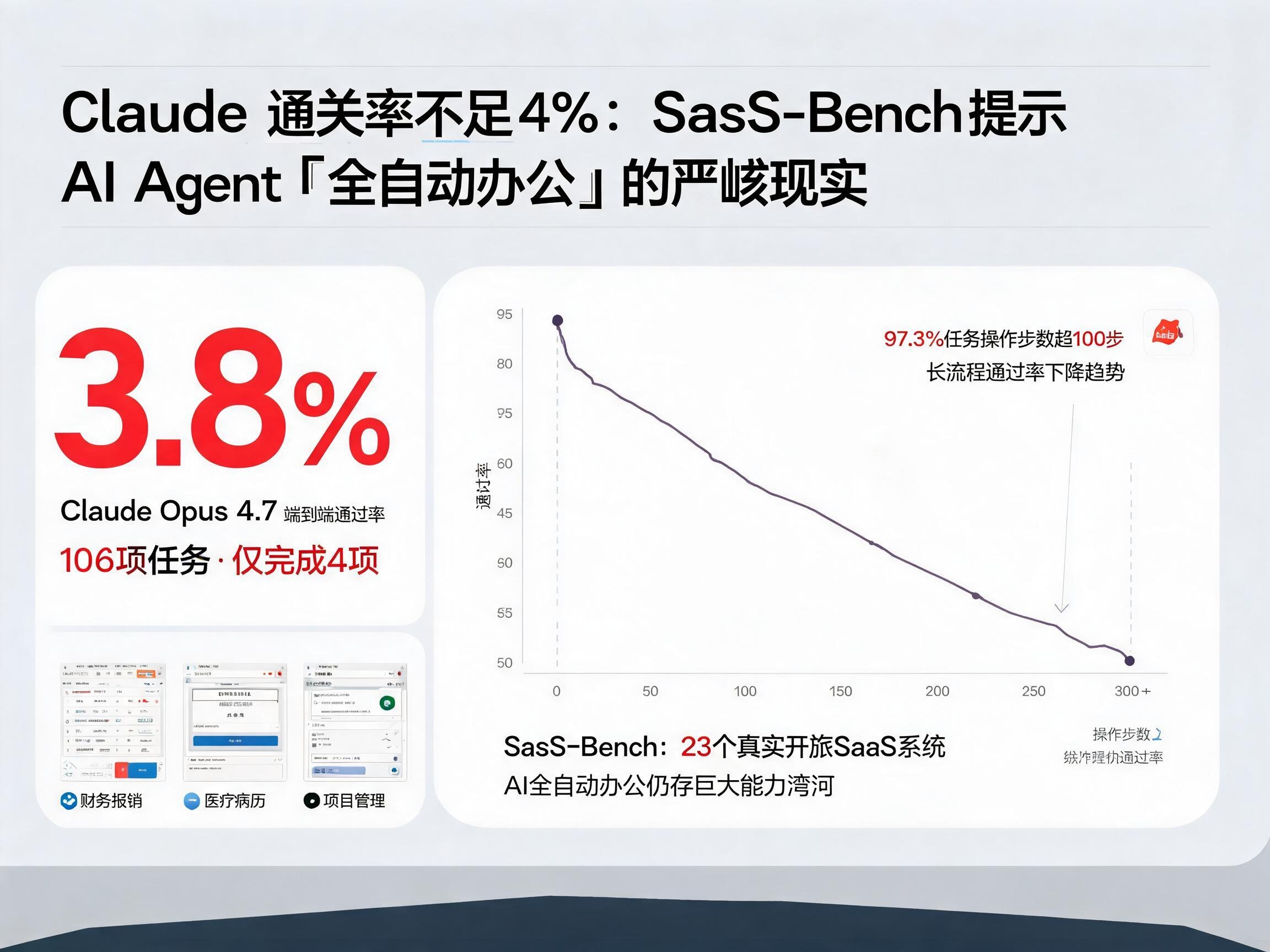
在人工智能飞速发展的今天,「全自动办公」的图景似乎触手可及。从项目管理到财务报销,再到复杂的医疗记录处理,我们似乎能看到 AI Agent 的身影活跃在各类日常办公场景中。然而,近期 UniPat AI 推出的 SaaS-Bench 评测,如同一盆冷水,猛烈地浇灭了许多人心中对 AI Agent 迅速取代人类工作的期待。特别是,Claude 等顶尖 AI 模型在这一严苛测试中的惊人低通过率——仅为 3.8%——直接撕碎了「Computer-Use」类 Agent 描绘的「全自动办公」幻想。
SaaS-Bench 的出现,并非为了给 AI Agent 的发展泼冷水,而是为了揭示当前 Agent 在真实、复杂工作场景下的局限性。它挑战了过去一年中许多评测中出现的「虚高」成绩,要求 Agent 在真正的 SaaS 系统中,模拟长达数百步的真实业务流程。这不仅仅是点击按钮或填写表格,而是需要理解业务目标、跨应用查找信息、保持状态一致,并最终将所有细节正确落地的复杂任务。
SaaS-Bench:一场真实工作场景的残酷考试
传统的 AI Agent 评测,大多局限于仿真环境、相对简单的任务,步骤往往在几十步以内。这与真实办公室工作的复杂性相去甚远。设想一下,一个医疗管理员需要完成从填写病历、上报、生成正式文档的一系列操作,或者财务人员需要处理报销申请、审批、打款、记账等跨越多个系统的流程。这些真实世界的工作,步骤多、依赖复杂、涉及多系统交互。
SaaS-Bench 的核心理念就是「暴力」地将真实系统搬进 Docker 环境。它精心挑选了 23 个开源的 SaaS 系统,覆盖软件研发、业务财务、医疗管理、团队协作、农业供应链、独立媒体等六大领域。这些系统并非空壳,而是部署了完整的前后端逻辑、数据库状态、业务约束,并填充了真实业务数据。Agent 面对的不是一个空白的测试页面,而是一个充满历史数据、干扰项和跨系统关联的真实工作环境。
严苛的评测设计:跨应用与长流程是常态
SaaS-Bench 的 106 个任务被设计得极其贴近真实。
- 跨应用性:93.4% 的任务需要 Agent 跨越至少两个应用,其中 53 个任务涉及三个以上应用。
- 长流程性:97.3% 的文本任务操作步数超过 100 步,最长轨迹甚至达到 300+ 步。
- 多模态:任务模态也更加多样,32 个任务涉及多模态理解。
这些任务的构建过程也颇为精细,结合了 LLM 生成和专家把关。AI 首先生成任务草稿,明确目标、跨应用依赖和验证要求,随后由专家进行人工筛选、修改和真实执行检查,确保任务的专业性、自然性、可完成性和可验证性。
惨淡的榜单:主流 Agent 全军覆没
SaaS-Bench 提供了两种评分指标:
- Resolved Score(完全通过分数):要求所有检查点都通过,严苛。
- Checkpoint Score(检查点分数):按权重计算部分检查点通过的比例,相对宽松。
结果令人震惊。即便是强大的 Claude Opus 4.7,其检查点分数高达 43.9%,但端到端完全通过分数仅为 3.8%,意味着在 106 个任务中,它只完整通过了 4 个。而 Kimi K2.5 和 Gemini 3.1 Pro 的完全通过分数更是直接归零。这组数据残酷地表明,目前的 Agent 能够处理工作流程中的部分中间环节,但在完成一个完整的长流程任务方面,能力几乎为零。
即使允许模型在同一任务上独立运行三次(Pass@k),Claude Sonnet 4.6 在多模态任务上的通过率从 33.9% 提升到 52.1%,这说明它们并非完全不行,而是执行极不稳定。这种不稳定性并非环境随机性,而是模型在决策点上的微小差异导致了执行路径的完全分叉,这让 Agent 的长程任务执行变得像一场「赌博」。
Agent 失败的四大结构性缺陷
SaaS-Bench 的真正价值在于,它揭示了 AI Agent 在真实复杂环境中面临的四大结构性失败模式:
1. 任务越长,越容易出错:不可逆的下降曲线
SaaS-Bench 的数据清晰显示,随着任务执行的深入,Agent 的通过率呈单调递减趋势。即使前期每个检查点的通过率很高,但当任务包含大量检查点时,全部通过的概率会急剧下降。模型在任务后期表现明显不如前期,呈现出一条不可逆的下降曲线。这表明 Agent 缺乏在长程任务中维持一致性表现的能力。
2. 一步错,步步错:错误的涟漪效应
Agent 在某个决策点产生的微小错误,可能就会触发错误的业务逻辑,导致后续所有操作都基于错误的状态进行。例如,Agent 错误地将个人客户创建为公司客户,后续的数十个与该实体相关的发票、付款、对账等操作都将挂在错误的实体下。一个看似微小的 3% 权重检查点错误,可能导致下游 30% 的分数损失,形成连锁失败。
3. 做完不检查,自以为是:缺乏反思闭环
许多 Agent 在执行完一系列操作后,会认为任务已成功完成,但实际上并未进行最终的复查。例如,Claude Opus 4.6 在发现日期错误并执行修改后,没有回到页面进行确认,直接提交了任务。验证器发现页面日期仍未更新,导致任务失败。这暴露了当前 Agent 框架普遍缺乏「严谨的反思闭环」机制,它们像一个不会检查自己作业的学生,在意图层面认为成功,而在状态层面却已失败。
4. 同一张考卷,成绩忽高忽低:路径依赖的随机性
如前所述,即使在完全相同的初始条件下,Agent 在同一任务上的执行结果也可能大相径庭。这种路径依赖导致了 Agent 表现的极度不稳定,让其在长程任务中的执行更像是一种随机猜测,而非可靠的自动化。这使得用户难以预测 Agent 的实际表现,也阻碍了其在关键业务流程中的应用。
展望未来:Agent 的新范式与软件设计的重塑
SaaS-Bench 带来的启示是深刻的。当前 Agent 的Benchmark 成绩与真实工作能力之间存在巨大的鸿沟。Agent 普遍缺乏对持久状态的有效推理能力,缺乏操作后的闭环验证机制,也缺乏从错误中恢复的能力。这些问题并非简单地通过增大模型规模或增加工程模块就能解决,它们指向了当前 Agent 范式的深层局限:在长程任务中,模型难以像人类一样「心里有数」,对全局状态的持续感知能力不足。
这不仅是技术债,更是当前 Agent 范式面临的天花板。Claude 等模型的表现,让我们意识到,想要 AI Agent 真正实现「全自动办公」,还有很长的路要走。
SaaS-Bench 摊开了 AI Agent 能力的真实地图。未来的发展需要突破现有的局限,可能需要新的 Agent 架构,能够更好地处理长程依赖、状态管理和自我验证。
更重要的是,SaaS-Bench 也揭示了当前软件形态的局限性。目前的 SaaS 应用是为人类用户设计的,界面、交互方式都围绕人类的眼睛和手指。但当 AI Agent 成为主要用户时,这些界面就可能成为累赘。未来的趋势或许不是让 Agent 去学习如何操作人类的软件,而是软件本身需要为 Agent 重新设计,使其更易于被 AI 理解和调用。面向人类的 SaaS,可能都需要为 Agent 的到来进行一次重塑。
尽管挑战严峻,但 AI Agent 的发展势不可挡。理解其当前的局限,才能更好地指引前进的方向。通过 Claude 官网、Claude 官方 等渠道,我们可以持续关注 Claude 国内使用 的进展,并探索 Claude 镜像站、Claude 官方中文版 等解决方案,但根本的突破,仍需在 Agent 的核心能力和软件生态的协同进化上发力。对于追求 Claude 教程 和 Claude 使用指南 的用户而言,理解这些评测结果,有助于更理性地评估 AI Agent 的实际价值,并为未来的应用做好准备。
Loading...