ARTICLE SIGNAL
具身智能新范式:WALL-WM事件级预测模型深度解析
深度解读WALL-WM,全球首个事件级预测具身智能世界模型。分析其从按帧学习到按事件理解的革命性转变,以及对机器人未来发展的深远影响。AI,具身智能,机器人,世界模型,事件级预测
type
status
date
slug
summary
tags
category
icon
password
网址
在人工智能飞速发展的浪潮中,具身智能(Embodied AI)正成为新的焦点。机器人能否像人类一样理解并适应复杂的物理世界,并执行多样化的任务,是衡量其智能水平的关键。近期,自变量机器人团队发布了全球首个“事件级预测”具身智能世界模型——WALL-WM,这标志着具身智能领域的一次重大突破。本文将深入解读WALL-WM的核心理念、技术创新及其对未来机器人发展的深远意义。
从“逐帧填空”到“抓重点”:具身智能的新范式
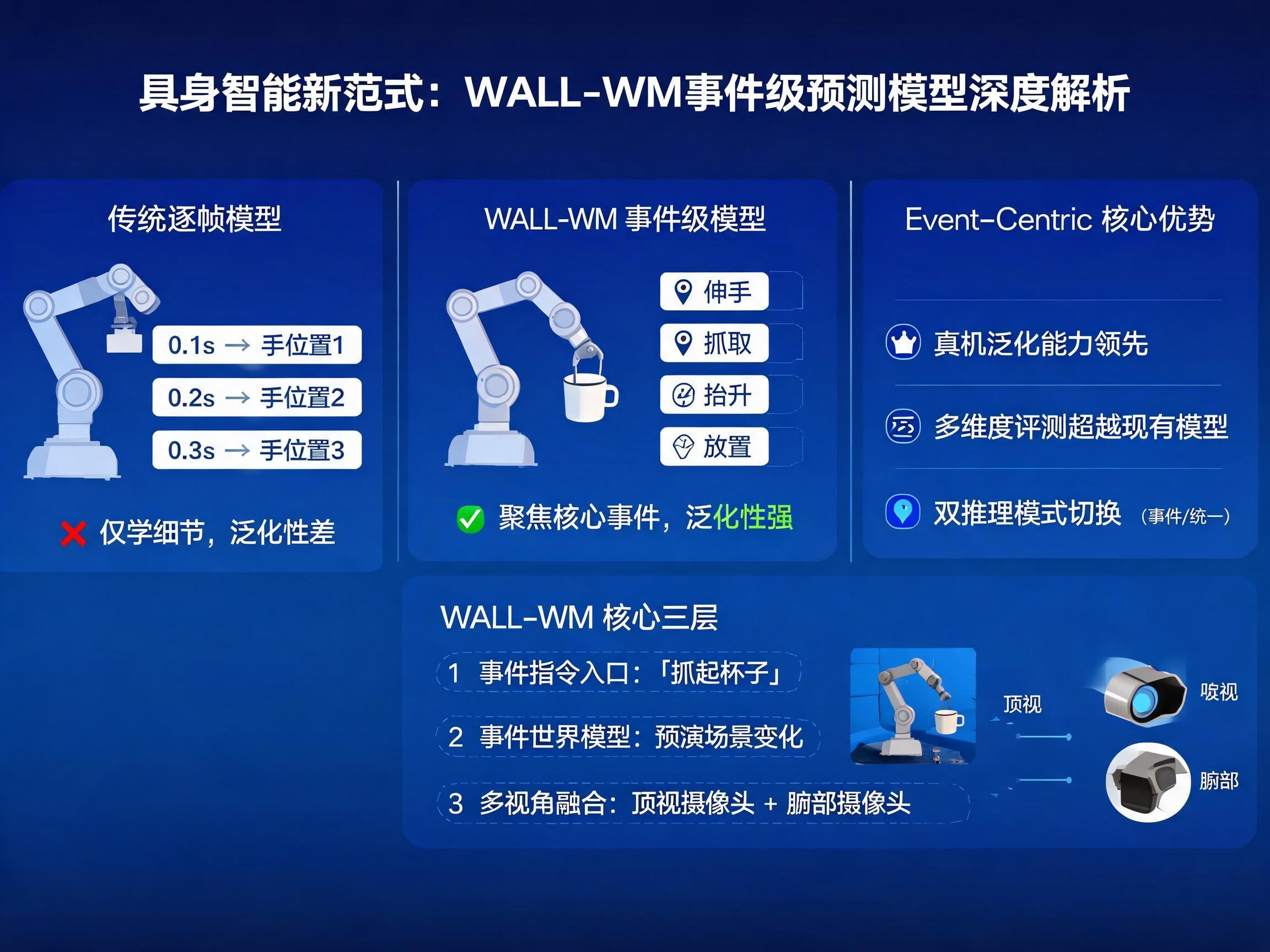
传统的具身智能模型在学习机器人动作时,往往采用“逐帧填空”的方式。即将一个完整的动作分解成极小的、连续的时间帧,然后让模型预测每一帧的细微变化。例如,让机器人递一个杯子,模型需要预测“0.1秒后手在哪里”、“0.2秒后手在哪里”……这种方法虽然工程化,易于训练,但存在一个致命缺陷:模型学习到的是“手指每帧移动几毫米”这样的低级细节,而非“抓住杯子”这个核心目标。一旦杯子形状改变、桌面不同,或者节奏稍有变化,模型就可能“翻车”。
WALL-WM带来的“事件级预测”则是一种全新的解法。它将模型的预测单位从抽象的时间帧,转变为具有语义和物理意义的“事件”。模型不再纠结于每一帧的细微变化,而是直接想象“抓住杯子”这一关键事件发生时的世界状态,并基于此想象同步生成抵达目标动作的轨迹。由于“事件”本身是跨场景、跨物体的通用语义抽象,WALL-WM在跨场景泛化能力上展现出明显更稳健的表现。这使得机器人干活时,能够更像人类一样“抓重点”,灵活应对物理世界的各种复杂情况。
Event-Centric:理解世界的新维度
传统VLA模型的局限性
近年来,主流的视觉-语言-动作(VLA)模型通常遵循一个模式:输入当前画面和语言指令,预测一段固定长度的动作块。这种做法固然方便训练,但现实世界的机器人动作并非总是按照固定的时间窗口发生。一个简单的抓取任务,可能包含接近、接触、夹紧、提起、移动、放下等多个阶段,每个阶段的物理状态和控制需求都截然不同。
自变量团队在论文中提出了一个“反常识”的判断:文本、视觉、动作这三类信息,在本质上难以完全对齐。它们在高维空间拥有不同的“流形几何”和“时间尺度”。文本是高层语义意图,视觉是连续演化的观察,而动作则受物理世界强约束,对接触状态、时间精度和微小扰动极其敏感。若强行将三者压入同一个共享空间,预训练表示很容易偏离其先验几何,导致VLA模型在真机上的表现远不如其底座VLM。
WALL-WM的Event-Centric思路
针对这些问题,WALL-WM回归到更根本的问题:机器人究竟应该以什么单位来学习一个动作?其核心思路是“Event-Centric”,即将机器人任务切分到具有真正语义和物理变化的关键“事件边界”上,并在这些事件数据上进行训练和执行。
例如,“伸手”、“抓取”、“抬升”、“移位”、“放置”都可以看作围绕动作展开的语义事件。这些事件既能被语言清晰描述,也能被视频完整记录,还能映射到机器人的具体动作轨迹。这种方式真正串联起了语言、画面和动作。WALL-WM通过围绕事件来理解世界变化,再将这种理解转化为可执行动作,这才更符合具身智能“世界模型”应有的形态。
WALL-WM的核心链路:先预演,再执行
WALL-WM并非直接从画面生成动作,而是重构了从感知到控制的路径,将其拆分为三层:
1. 事件指令入口
这是任务的起点,直接告知模型“下一步要做什么”,如“抓起杯子”、“放进篮子”等。
2. 事件世界模型
模型围绕指令事件,预演接下来画面中的变化:物体如何移动、场景如何演变、机械臂应如何介入。
3. 多视角时空融合
机器人通常拥有多个摄像头(如顶视、腕部),WALL-WM会将这些不同视角的输入融合同步,使模型在执行动作前,能更全面地感知现场环境。
关键设计:保留视频先验,长出动作能力
* 同一基座,两种推理模式:
* 事件模式(Event Mode):当有上层规划器拆分好任务时,模型直接根据事件描述输出长度可变的动作,顺应语义事件自然展开。
* 统一模式(Unified mode):在无外部规划器时,模型结合视觉输入和指令,在线生成中间推理,输出固定长度的动作块,适合实时闭环控制。
这两种模式共享同一套模型权重,并可在执行过程中切换,无需重新训练,增加了灵活性。
* 视频模型和动作模型分工生长:
WALL-WM不直接将视频模型改造为动作模型,而是将二者“拆开”生长。视频模型利用互联网视频训练的动态先验,理解物体和场景变化;动作模型则从零初始化,专门学习将视觉变化转化为机器人轨迹。两者通过单向耦合,动作流读取视频流的视觉证据,视频流保留动态先验,避免被动作数据过早“带偏”。这确保了模型既拥有强大的世界理解能力,又能持续增长动作能力。
* 几何感知的多视角融合:
为解决多视角数据不对齐问题,WALL-WM引入了“视锥掩码”(判断三维空间关联性)和“管状掩码”(随机遮挡区域,强制模型跨视角寻找线索)。这些机制配合免标定、可学习的相机位姿编码,实现了天然支持多本体、多视角的混合训练,使跨视角注意力成为训练中反复使用的几何对应能力。
* 阶梯式思维链解码:
为了解决传统CoT解码的延迟问题,WALL-WM采用了“Staircase Layer-Relay CoT Decoding”。底层抽取共用推理状态一次,高层思维token并行完成,保留了可解释性的同时,显著减少了延迟,实现了可解释性与实时性的兼顾。
从数据到部署:系统级重构
WALL-WM的强大能力不仅源于模型结构,更在于其从数据采集到部署的系统级重构:
数据金字塔与分层标注
- 数据结构:构建了从百万级通用网络视频,到人类动作视频、第一视角视频、公开机器人数据,再到真机接管数据的“数据金字塔”,逐层逼近真机部署需求。
- 分层标注与采样:采用四级层级化标注(任务、子任务、动作、片段)和双聚类采样,将轨迹拆解为边界清晰的行为单元。这不仅帮助模型理解动作边界,还使稀有指令和特殊场景组合在训练中更容易暴露,改善了数据分布,有效训练长尾样本。
高效训练与优化部署
- 底层训练系统:采用分布式“Muon”提升收敛性和稳定性,并用“多事件打包”降低单样本计算浪费。
- 部署优化:通过蒸馏减少去噪步数,FP8量化降低显存和推理成本,使模型更适合机器人实时控制所需的低延迟要求。
实验结果与未来展望
在多项关键实验中,WALL-WM展现了其在“真机泛化能力”上的巨大价值。无论是固定模板任务还是新指令、新物体、新场景,它都能稳定完成动作推理与执行。
- Embodied Video Generation:在Motion Quality、Semantic Consistency、Physical Plausibility等维度全面领先。
- 3D Awareness (CO3Dv2):在Point Error与Depth Error上优于现有模型。
- 真机Core15 L1基准:在基础任务、推理任务、灵巧操作及泛化场景下,任务完成度显著超越现有模型,成为当前L1模型中的佼佼者。
柏拉图在《斐德罗篇》中提到“依乎天理,因其固然”,这句话恰恰点出了WALL-WM的核心思想。物理世界的真实任务从未按固定时间窗口发生,而是像一串自然衔接的事件。WALL-WM沿着这些“事件关节”去理解世界、预测变化、生成动作,为机器人的泛化能力找到了一个更自然的支点。
随着具身智能竞争从演示走向真实部署,核心将转向“谁更能理解变化、组织行动、稳定泛化”。自变量机器人团队此次推出的WALL-WM,以一套自洽的工程化范式,提前展现了这条赛道的领先成果,为具身智能的未来发展开辟了新路径。
Loading...