.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
AI决策革命:OpenAI新范式,代码替代参数更新!
type
status
date
slug
summary
tags
category
icon
password
网址
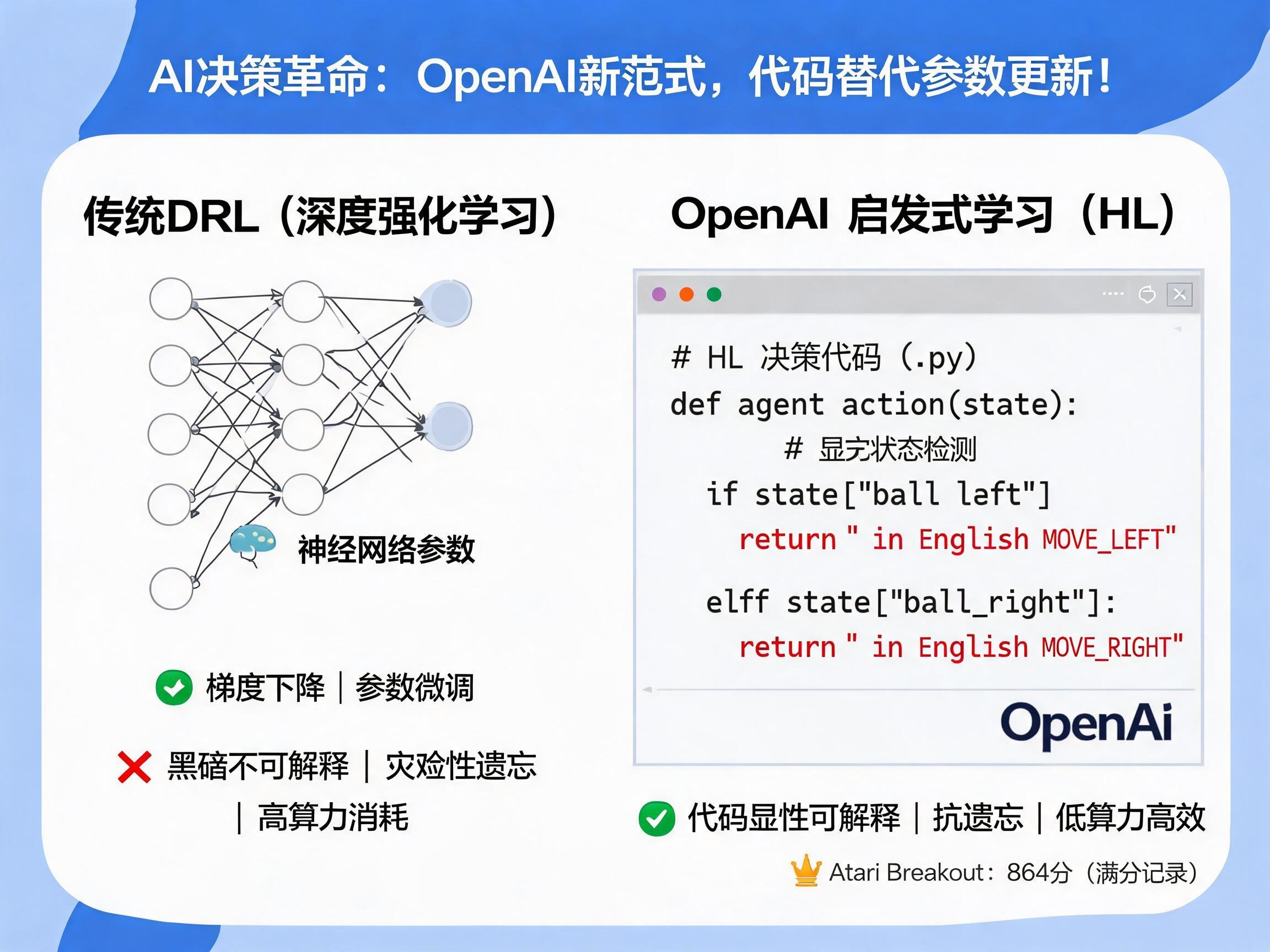
在人工智能的飞速发展浪潮中,强化学习(Reinforcement Learning, RL)一直是驱动AI智能体学习和决策的关键技术。然而,传统的深度强化学习(Deep Reinforcement Learning, DRL)依赖于复杂的神经网络模型,其训练过程涉及海量的参数更新和梯度优化,这不仅带来了“黑箱”决策、灾难性遗忘和低样本效率等诸多瓶颈,也限制了AI的可解释性和落地应用。
近期,OpenAI的核心研究员翁家翌提出了一种极具颠覆性的强化学习新范式——启发式学习(Heuristic Learning, HL)。这项创新彻底打破了AI必须通过参数更新来学习的固有认知,提出了一种“无需训练参数,决策只需AI手搓一个.py文件”的全新路径,为AI的自主决策和持续学习开辟了新纪元。
颠覆传统:从参数更新到代码编辑
传统深度强化学习的核心在于通过优化神经网络的权重参数来存储和调整策略。当AI接收到环境的观测(如游戏画面)时,神经网络内部复杂的计算会映射出相应的动作。然而,这种“黑箱”式的决策过程使得我们难以理解AI为何做出某个决定,也难以对其进行精细的干预和调试。
HL范式则提供了一个截然不同的视角。它不再将决策策略存储在不可见的神经网络参数中,而是将其迁移到离散的程序代码空间。这意味着,AI的学习过程不再是盲目的梯度下降,而是显式的代码编辑与迭代。AI不再是训练一个模型,而是构建和维护一个完整的、智能化的软件系统。
这个系统包含:
* 显式的状态检测器:清晰识别当前环境状态,例如“小球位于左上方,速度向右”。
* 显式的规则逻辑:用可读的代码定义状态到动作的映射,例如“如果球将落在左侧,则向左移动”。
* 完整的软件工程实践:包括测试用例、回归检查、失败记录和版本历史。
每一次迭代,AI(例如由GPT-5.4驱动的Codex)会审视系统的整体表现,分析失败案例和日志,然后进行结构性的代码调整,而非仅仅是参数的微调。
启发式学习的核心优势:知识的显性化与可传承
HL范式带来的最显著优势在于知识的显性化。与参数存储的易被覆盖不同,HL将知识转化为模块化的代码和测试。这意味着:
- 抗遗忘性:旧有的能力不会因为新任务的学习而被覆盖,而是被封装成可调用的模块,确保知识的持久性和可复用性。
- 可解释性:决策逻辑清晰地体现在代码中,研究人员可以轻松理解AI的决策过程,甚至进行人工干预和优化。
- 高效率:通过代码编辑和逻辑推理,AI能够更高效地学习和适应新环境,显著减少了对海量交互数据的依赖,从而降低了算力消耗和研发成本。
翁家翌的研究表明,HL在多项任务中,包括经典Atari游戏和复杂的机器人仿真,其性能已能与甚至超越老牌强化学习算法如PPO。在Breakout游戏中,HL甚至达到了理论满分864分,这在没有神经网络训练和梯度更新的情况下,无疑是一项里程碑式的成就。
实际应用与未来展望
HL在游戏和机器人控制领域的成功验证了其潜力。在Atari 57大规模测试中,HL的中位表现与主流DRL算法持平,并在多款游戏中超越人类玩家基准。在MuJoCo机器人连续控制任务中,HL从基础步态规则出发,逐步迭代优化,最终在Ant四足机器人任务上取得了对标专业DRL模型的优异成绩。
然而,翁家翌也坦承,HL并非万能。从原始像素中进行目标识别和特征抽象,仍然是深度神经网络的强项。HL的核心价值在于策略的持续迭代和环境的长期自适应。
未来的关键命题在于如何将深度神经网络的感知能力与HL的显性化策略迭代能力有机融合。一种极具前景的思路是:
1. 利用HL实时处理在线环境数据流,快速沉淀可复用的在线行为经验。
2. 将这些显性化的经验整理、内化,转化为高质量的数据集。
3. 利用这些数据集周期性地迭代更新神经网络,形成一个“感知-决策-优化”的闭环,同时兼顾AI的持续学习能力和可解释性。
这种融合有望解决AI在复杂动态环境中长期自主学习和适应的难题,推动AI技术在更广泛的领域实现突破性应用。启发式学习(HL)范式,以其独特的“代码即决策”理念,正引领我们走向一个更加智能、透明和高效的AI新时代。
Loading...