.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
API揭秘大模型参数量?GPT、Claude、Gemini参数之争
type
status
date
slug
summary
tags
category
icon
password
网址
API调用能否揭开大模型参数量的神秘面纱?
最近,AI领域最令人瞩目的话题之一便是:仅凭黑盒API调用,我们是否能够准确估算出像GPT、Claude、Gemini这类顶级大型语言模型(LLM)的参数量?一个名为“不可压缩知识探针”(Incompressible Knowledge Probes, IKP)的研究框架,由研究人员李博杰在arXiv上发布的一篇论文《Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity》引起了技术社区的轩然大波。这项研究的初衷,以及由此引发的关于模型参数、性能和成本的讨论,正以前所未有的方式挑战着我们对闭源大模型的认知。
“不可压缩知识探针”:核心理论与方法论
这项研究的灵感来源于一个持续了三年的非正式测试。研究团队长期向不同版本的主流大模型提出一个冷门问题:“你了解中科大Hackergame吗?”(一项CTF网络安全竞赛)。通过观察模型对这一特定冷门知识的掌握程度随时间的变化,研究者们发现,尽管模型的逻辑推理能力可以通过训练技巧进行优化或“压缩”,但对于冷门、事实性的知识,其记忆容量似乎与模型的物理参数规模紧密相关,且难以被大幅压缩。
基于这一核心假设,研究团队构建了一个包含1400个问题的IKP数据集,这些问题按信息稀缺程度分为7个层级。他们在大量已知参数量的开源模型上进行了实验,拟合出了事实准确率与参数量之间的对数线性关系(R² = 0.917)。随后,他们将这一模型应用于闭源大模型,试图通过API调用其对这些冷门知识的回答准确性,来反推其参数规模。
惊人估算与社区的“炸裂”反应
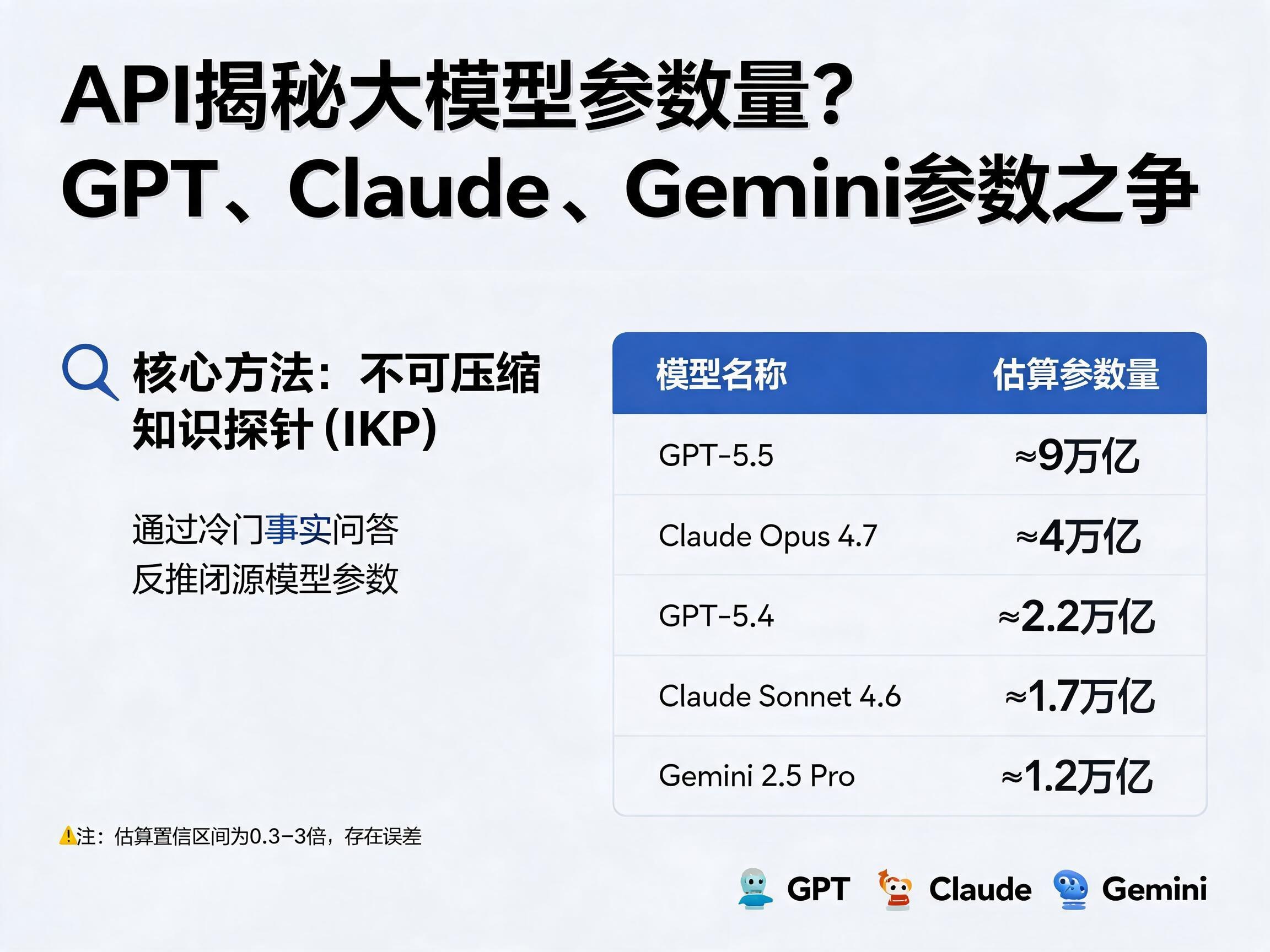
根据IKP方法,论文给出了令人震惊的参数量估算(90%置信区间约为0.3至3倍):
* GPT-5.5:约 9 万亿参数
* Claude Opus 4.7:约 4 万亿参数
* GPT-5.4:约 2.2 万亿参数
* Claude Sonnet 4.6:约 1.7 万亿参数
* Gemini 2.5 Pro:约 1.2 万亿参数
这些数字一经公布,立刻在技术圈引发了“炸裂”般的讨论。一些博主更是基于这些估算,结合主观体验,推演出了一套关于算力储备、模型迭代与竞争格局的完整叙事。例如,有人猜测Anthropic因算力限制,被迫“反向升级”了Claude Opus 4.7的参数量,而OpenAI则凭借充足算力将GPT-5.5推至9万亿。
争议与质疑:方法论的局限性
然而,这项研究并非没有争议。多位研究者和从业者对估算结果及其方法论提出了质疑:
- “事实知识不可压缩”的挑战:定向引入“合成数据”进行微调,能够显著提升模型对冷门知识的掌握度,这直接干扰了“事实知识不可压缩”的核心前提。模型的性能提升可能并非完全来自参数量的增加,而可能包含更高效的数据利用或微调策略。
- 参数量与性能的比例失调:如果Gemini 2.5 Pro和Claude Sonnet的参数量估算(约1.7T)与国内模型Kimi K2.6和GLM 5.1(约800B)差距仅在两倍左右,那么两者之间巨大的性能鸿沟难以仅用参数量差异来解释。
- 与已知信息的巨大出入:业内长期流传的GPT-4规模约为1.7T,这与论文估算结果存在巨大差异。如果GPT-4已经是1.7T,那么GPT-5.5达到9T的跨越式增长,其带来的性能提升幅度是否与10倍参数差距相匹配,也引发了疑问。
- 置信区间过大:发起讨论的博主也强调,这些数字不应被视为事实,置信区间非常大,某些模型的估算可能相差甚远。
建设性的探讨与未来方向
尽管存在争议,这项研究也激发了许多建设性的讨论。例如,有观点提出,混合专家模型(MoE)与稠密模型在知识压缩效率上可能存在本质差异。MoE架构下,事实知识可能分散在不同的专家网络中,建议将这两类模型分开统计以观察趋势。
这项研究的价值在于,它提供了一种通过API接口探索闭源大模型内部机制的创新思路。虽然其当前的估算可能存在误差,但它点燃了关于如何更深入、更客观地理解和评估这些“黑盒”模型的火花。
对于希望利用先进AI能力的开发者和企业而言,了解这些模型的潜在规模和能力边界至关重要。虽然直接获取精确的参数量信息几乎不可能,但我们可以通过稳定的API接入,如国内领先的大模型API直连服务,来实际测试和集成各类模型。这些服务能够帮助您低价API服务,国内中转API,并提供如Claude API、gpt API、gemini API等多种选择,让您在实际应用中,根据性能、成本和需求,选择最适合的模型,而非仅仅依赖估算数据。
未来,我们期待更多此类研究的出现,它们不仅能帮助我们更准确地理解大模型,也能指导我们更有效地利用这些强大的工具,无论是Claude国内使用的便利性,还是ChatGPT国内如何使用的优化,都将受益于对模型特性更深层次的洞察。
---
免责声明:本文内容基于公开研究和社区讨论,旨在提供信息和引发思考,不代表任何模型官方立场。模型参数估算具有不确定性,实际应用请以官方发布信息和实际测试为准。
Loading...