.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
Agent困境:Claude上下文失焦与7大记忆管理工具深度解析,玩转Claude官方
type
status
date
slug
summary
tags
category
icon
password
网址
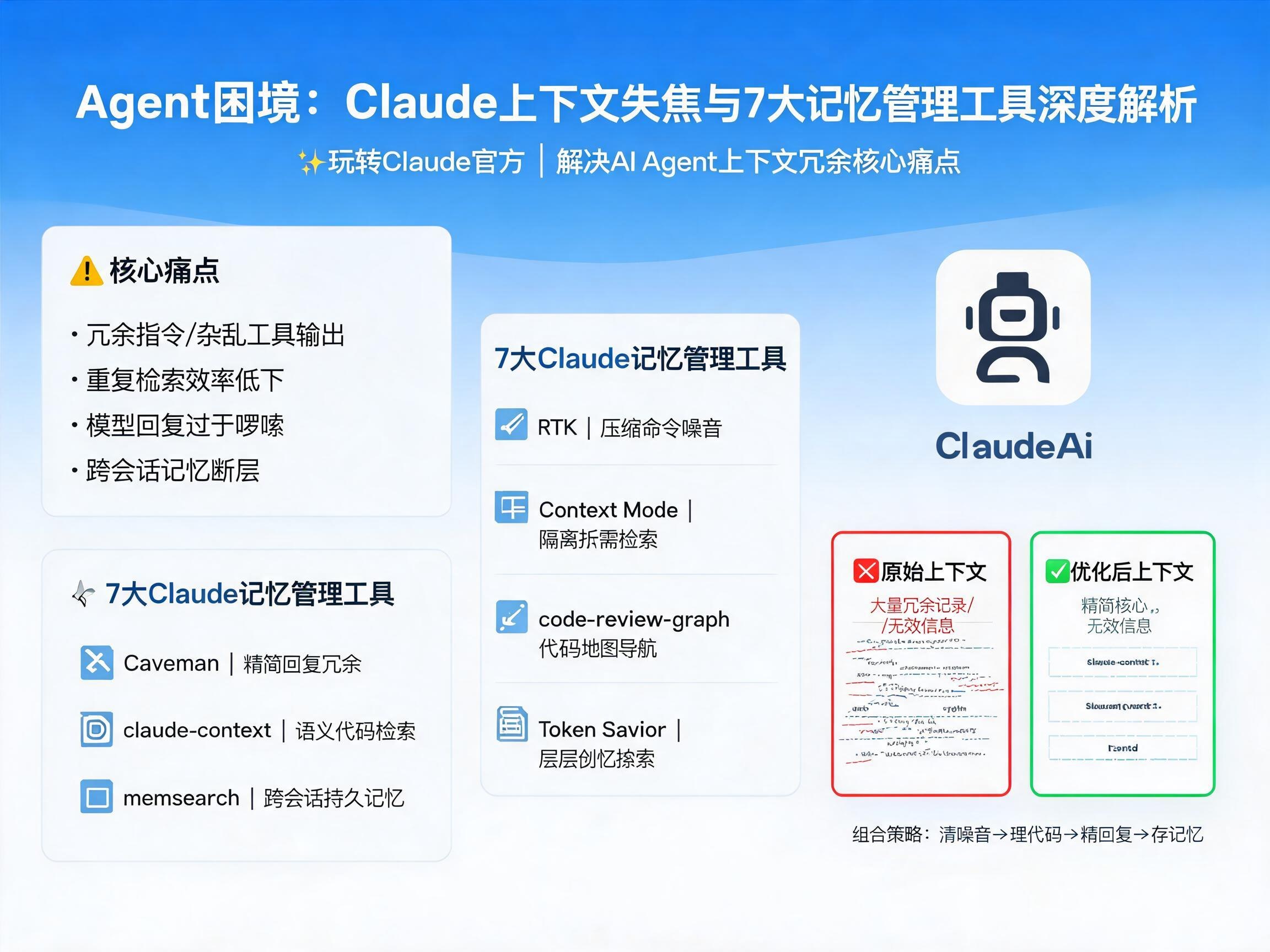
Agent的“记忆”困境:上下文失焦为何成为致命伤?
在AI Agent日益普及的今天,我们常常会遇到一个令人头疼的问题:Agent在多轮交互中,似乎总是“健忘”且“啰嗦”。尽管像Claude这样的大模型已经拥有惊人的1M上下文窗口,但这非但没有解决问题,反而助长了许多人忽视上下文管理的风气。结果是,大量的冗余信息被一股脑地塞进上下文,导致Agent输出质量直线下降,甚至陷入低质量回复的恶性循环。正如文章所预警的,“2026,Agent死于上下文失焦”并非危言耸听,而是对当前AI Agent发展中核心痛点的深刻洞察。
尤其是在需要串联多轮任务、频繁调用工具的AI Agent场景中,这个问题更为突出。Agent会产生海量的交互记录、工具调用结果和过程输出,其中大部分对最终结果并无意义。如果缺乏有效的过滤和清理机制,这些无效日志、过期指令和重复对话将不断堆积,不仅严重影响Agent的输出效果,还会急剧增加运营成本。那么,究竟是什么导致了Agent的上下文失焦?主要症结通常体现在以下五个方面:原始指令表述过于冗余、工具调用输出内容杂乱、代码库重复检索效率低下、模型回复过于啰嗦以及跨会话与跨Agent之间的记忆断层。
幸运的是,针对这些高频痛点,社区已经涌现出了一系列专为Claude Code设计的记忆遗忘与管理工具。它们旨在分层解决上下文冗余问题,帮助我们更好地驾驭Claude官方模型,提升Agent的智能表现。
核心痛点与7大Claude Code工具的创新解决方案
为了让Agent真正成为高效的助手,而非“信息垃圾桶”,我们需要从根源上解决上下文管理的难题。以下七款适配Claude Code的工具,为我们提供了全面的解决方案:
1. RTK:压缩原始命令,聚焦核心信息
许多开发者在使用Claude Code时,会发现终端命令(如
git status、pytest)的原始输出包含了大量环境信息和无关描述。RTK工具通过介入Shell与Claude之间,利用Claude Code的PreToolUse Hook拦截并轻量化压缩这些命令行噪音。例如,git status的冗长输出被精简为只保留修改文件和变更数量;pytest的详细日志则只显示失败用例和报错原因。这种预处理机制极大地减少了模型需要处理的无关信息,让Claude能够更快地捕捉到核心需求,优化Claude国内使用体验。2. Context Mode:隔离工具巨量输出,按需检索
当Agent需要运行自动化测试、读取超长日志或抓取页面DOM时,工具往往会返回完整、冗余的文本。Context Mode的创新之处在于,它将这些大块工具内容隔离存储在本地沙盒与SQLite数据库中,不直接灌入主对话上下文。模型仅接收极简摘要与索引标记。只有当模型需要细节时,才通过Hook回调触发精准的按需检索。这对于重度Playwright、GitHub、日志流用户以及那些因工具定义和输出占据大量上下文的Claude官方用户而言,是提升效率的关键。
3. code-review-graph:构建代码地图,引导Claude高效探索
在大型代码仓库中,Claude常常会“迷失方向”,为了回答一个简单问题而反复读取大量文件。code-review-graph通过Tree-sitter解析代码,将函数、类、导入、调用等信息抽离并构建成一张结构图。这张“代码地图”被存储在SQLite中,Agent在执行任务前先获取最相关的结构信息,而非盲目地读取整个仓库。这不仅大幅缩短了Claude的探索时间,对于管理大型monorepo或进行代码审查尤其有效,是提升Claude教程中代码理解能力的重要一环。
4. Token Savior:分层检索,按需展开代码细节
Token Savior解决了直接将相关代码整段吐给模型的问题。它采用分层检索机制:首先提供索引和短摘要;如果需要,再给出代码片段;最后,在确认必要时才提供完整代码。它还包含一个Compact Symbol Cache,避免重复读取已看过的符号,只在代码实际变更或用户明确要求时才展开全文。这种“先给最少的,再按需要逐级展开”的策略,极大地优化了Token的使用效率,是Claude官方模型上下文管理的重要实践。
5. Caveman:精简Claude回复,告别冗余“废话”
Claude虽然智能,但也可能出现回复过于啰嗦、礼貌用语过多、过度解释等问题,浪费宝贵的Token。Caveman插件专为此设计,它依托Claude Code的Skill/Plugin层运行,通过SessionStart、UserPromptSubmit等Hook自动生效,从根本上收紧Claude的表达习惯。它会砍掉礼貌语、连接词、包装句和无意义的三段论,但保留核心知识点。此外,它还能自动压缩每次会话加载的CLAUDE.md长文本,只精简自然语言的“废话”,完好保留代码块、路径、命令等关键信息。
6. Claude-context:语义检索,高效召回代码块
在大仓库中,Agent反复“摸索”寻找相关代码的效率极低。claude-context通过将仓库切块、做embedding并存储到向量数据库,为Claude提供了一层语义检索能力。当Agent需要回答问题时,它不再需要从头遍历整个仓库,而是先召回最相关的代码块。这种方式极大地提高了Claude在大型代码库中检索的效率,避免了重复的试错过程,让Claude国内使用更加顺畅。
7. memsearch:跨会话、跨平台的持久记忆管理
Agent的“记忆断层”是另一个重大挑战。memsearch旨在解决跨session、甚至跨平台的记忆复用问题。它不依赖黑盒数据库,而是将可读可编辑的本地Markdown文件作为唯一的真实记忆源,向量数据库仅作为临时、可重建的检索索引。这种Markdown-first的设计,让人工可以直接阅读、修改和管理AI的记忆,并支持版本控制和多人协作。它通过SessionStart、UserPromptSubmit、Stop、SessionEnd等Hook捕获和注入记忆,并采用三层渐进式检索,确保主对话不被记忆检索过程污染,只返回整理过的结果。memsearch让Claude能够记住历史讨论细节,避免每次新session都从零开始,是实现Agent长期智能和提升Claude官方中文版体验的关键。
7大工具组合策略:构建高效Agent工作流
这些工具并非孤立存在,它们的组合使用能发挥出更大的效能。一个推荐的组合使用顺序是:
- 清理噪音与减负: 首先使用 RTK 清理终端的杂乱日志和工具输出,再通过 Context Mode 隔离和管理大型工具的原始输出,确保上下文只包含高价值信息。
- 提升代码理解: 针对大型代码库,部署 code-review-graph 构建代码地图,或使用 claude-context 进行语义检索,帮助Claude迅速理解项目结构和定位相关代码。
- 优化模型交互: 结合 Token Savior 实现代码的分层检索,按需展开信息,避免一次性加载过多不必要的代码。同时,利用 Caveman 精简Claude自身的冗长回复,提高信息密度。
- 构建持久记忆: 最后,引入 memsearch 解决跨会话的记忆断层问题,确保Agent能够学习和复用历史经验,实现真正意义上的长期智能。
简单来说,就是“先清噪音减负,再让AI看懂代码,最后精简回答、留住所有历史记忆”。通过这样的组合拳,我们不仅能有效避免Agent陷入上下文失焦的困境,还能大幅提升Agent的效率、降低运营成本,从而更好地发挥Claude官方模型的强大能力。无论您是进行Claude国内使用还是探索Claude教程的进阶技巧,这些工具都将是您不可或缺的利器。让我们一起告别Agent的“记忆遗忘症”,迈向更智能、更高效的AI Agent时代。
结语
Agent的上下文失焦问题,是大模型时代我们必须直面并解决的挑战。通过深入理解其痛点,并巧妙运用RTK、Context Mode、code-review-graph、Token Savior、Caveman、claude-context和memsearch这七大Claude Code记忆管理工具,我们能够有效地优化Agent与Claude官方模型的交互,提升Agent的整体性能和用户体验。这些工具不仅是技术的创新,更是对Agent未来发展方向的指引,预示着一个更加智能、高效且“有记忆”的AI Agent时代的到来。探索更多Claude相关功能和获取Claude使用指南,请访问Claude官网。
Loading...