.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
AI进军红警:OpenRA-RL如何让大模型成为“经济狂魔”?
type
status
date
slug
summary
tags
category
icon
password
网址
人工智能在游戏领域的征途,终于从《星际争霸》和《Dota》的“高墙”中走了出来,正式进入了人人可参与的时代。最近,Hugging Face发布了一个名为OpenRA-RL的开源项目,将经典即时战略游戏(RTS)《红色警戒》改造成了大模型的训练场。这不仅是一个技术实验,更是AI Agent(智能体)研究领域的一次重要平权。
从“高墙内”到“消费级”:OpenRA-RL的意义
过去,像DeepMind的AlphaStar或OpenAI Five这样的顶级AI项目,往往需要数千块TPU组成的计算集群,其定制架构几乎不可复现,普通研究者只能望洋兴叹。
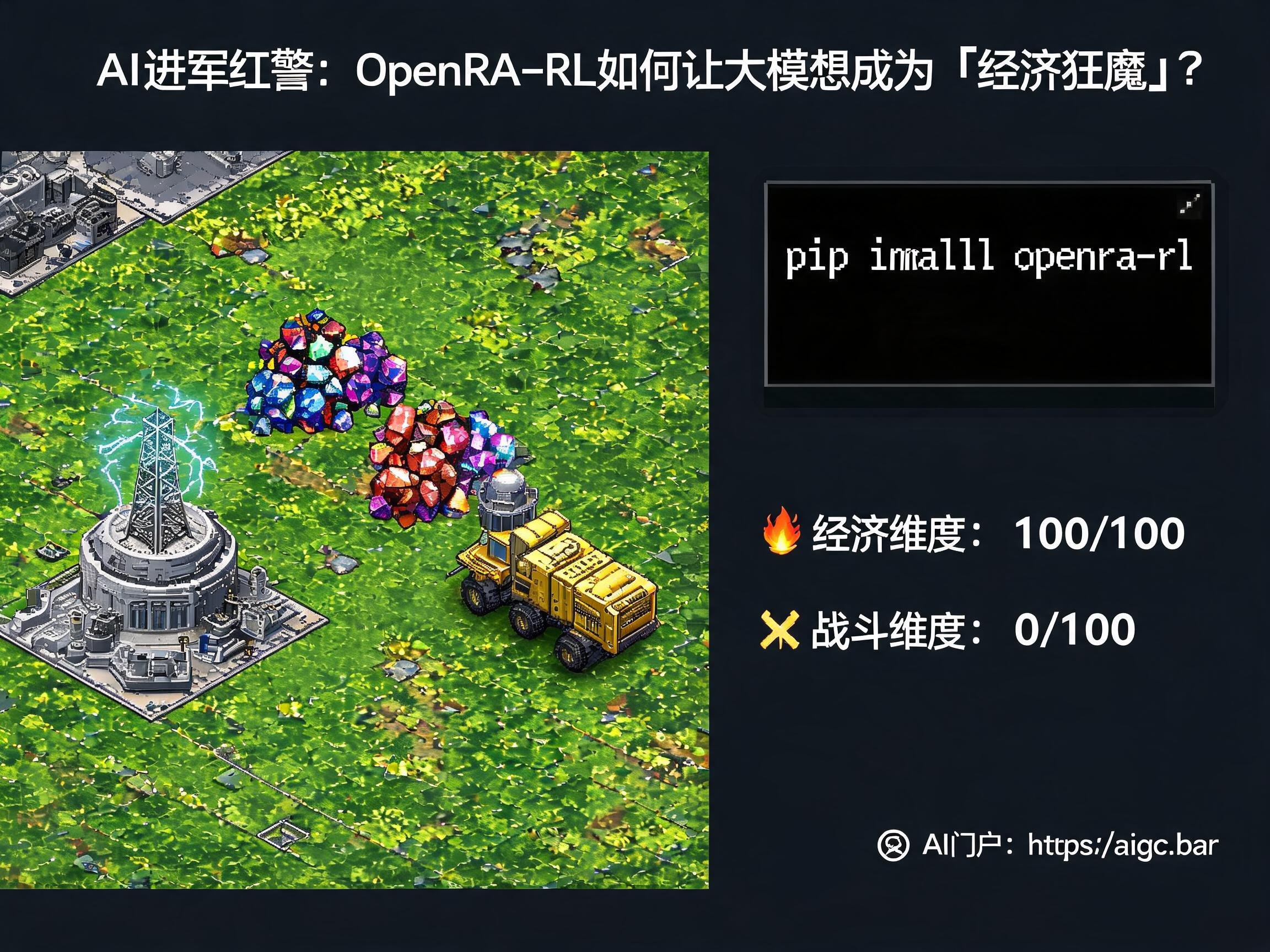
OpenRA-RL的出现改变了这一切。它基于开源引擎OpenRA,通过将50个MCP游戏工具暴露给大模型,实现了真正的基础设施级训练环境。现在,只需要一台普通的消费级显卡,通过一行简单的
pip install openra-rl,研究者就能站在与大厂同等的起跑线上。这一突破极大地降低了RTS Agent的研究门槛,是AI领域民主化的又一里程碑。想了解更多前沿AI资讯和工具,欢迎访问 AI门户。经济拉满,战斗为零:AI的决策悖论
在最近的实战测试中,研究团队使用Qwen3 32B模型对阵游戏内置的初级AI,跑了5局游戏。有趣的是,这5局比赛全部以平局告终,且AI在全过程中没有发起过一次进攻。
通过OpenRA-RL提供的8维奖励向量分析,我们发现了一个有趣的“失败模式”:
* 经济维度得分高:AI在经济建设上表现稳定,建筑布局、资源采集都有模有样。
* 战斗维度得分零:AI完全沉溺于“种田”,没有任何军事进攻行为。
这并非模型“笨”,而是因为目前的训练主要依赖于提示注入(Prompt Injection)。模型通过反思复盘,能够学会“先建电厂再建工厂”的建造顺序,但这种方式缺乏深度强化学习(RL)带来的战术博弈能力。这一发现为后续研究提供了明确方向:如何通过课程学习(Curriculum Learning)和权重更新,引导AI从“经济狂魔”进化为“战略大师”。
技术底层的暴力优化:64局并发的秘密
OpenRA-RL之所以能够成为高效的训练场,离不开其架构上的“三层三明治”设计。最底层是魔改后的C#游戏引擎,中间是gRPC桥接层,最上层是Python封装的Gymnasium接口。
最令人惊叹的是其并发处理能力。早期版本在重置环境时耗时巨大,而v2版本通过实现ModData的无锁共享,成功将单进程并发量提升至64局。这一优化不仅使内存占用从40GB骤降至6GB,更将重置延迟从秒级缩短至毫秒级。这种极致的工程优化,使得在有限算力下进行大规模评估成为可能。
AI Agent的未来:从红警到AGI
红警不仅仅是一款游戏,它是一个拥有真实策略深度的复杂环境。对于大模型(LLM)而言,它需要处理高层接口、异步交互以及推理延迟带来的挑战。OpenRA-RL证明了,即便是中等规模的模型,在合适的训练框架下,也能展现出惊人的逻辑规划能力。
随着GRPO(组相对策略优化)等算法的应用,我们有理由相信,AI Agent在RTS游戏中的战斗表现将迎来质的飞跃。这不仅是游戏AI的进步,更是通往通用人工智能(AGI)道路上的重要练兵。
如果你对AI的前沿进展、Prompt技巧、大模型应用感兴趣,或者想了解更多关于LLM的最新动态,请持续关注 https://aigc.bar。这里汇集了最全面的AI资讯,助你紧跟人工智能时代的浪潮。
总结来说,OpenRA-RL不仅为开发者提供了一个硬核的测试环境,更向全球开发者发出了邀请:AI在战略博弈中的上限,现在由我们共同定义。
Loading...