.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
Qwen3.5+Milvus+ColQwen2:构建PDF多模态RAG知识库全指南
type
status
date
slug
summary
tags
category
icon
password
网址
引言:多模态 RAG 时代的到来
在人工智能领域,检索增强生成(RAG)技术早已成为解决大模型幻觉、提升专业领域问答准确性的标配。然而,传统的 RAG 架构长期受困于“文本提取”的瓶颈:面对复杂的 PDF 扫描件、图文混排的研报、含有大量公式和表格的论文,传统的 OCR 或文本解析工具往往会丢失关键的视觉信息。
随着 Qwen3.5-397B 这一旗舰级开源多模态大模型的发布,以及 ColQwen2 视觉向量模型的成熟,我们终于迎来了一种全新的范式——基于 PDF 的多模态 RAG。本文将深入解读如何利用 Qwen3.5、Milvus 向量数据库以及 ColQwen2,从零构建一个能够直接“读图”并精准回答问题的智能知识库。更多前沿 AI 资讯,欢迎访问 AIGC 门户。
架构核心:Qwen3.5 与 ColQwen2 的技术突破
Qwen3.5 作为当前开源多模态大模型的佼佼者,其架构设计的精妙之处在于 MoE(混合专家模型) 与 线性注意力机制(Linear Attention) 的结合。
- 高效的 MoE 架构:Qwen3.5 虽然拥有 397B 的总参数量,但在实际推理时,激活参数仅为 17B。这意味着它在保持万亿级模型性能的同时,大幅降低了推理成本和硬件门槛,实现了极高的性价比。
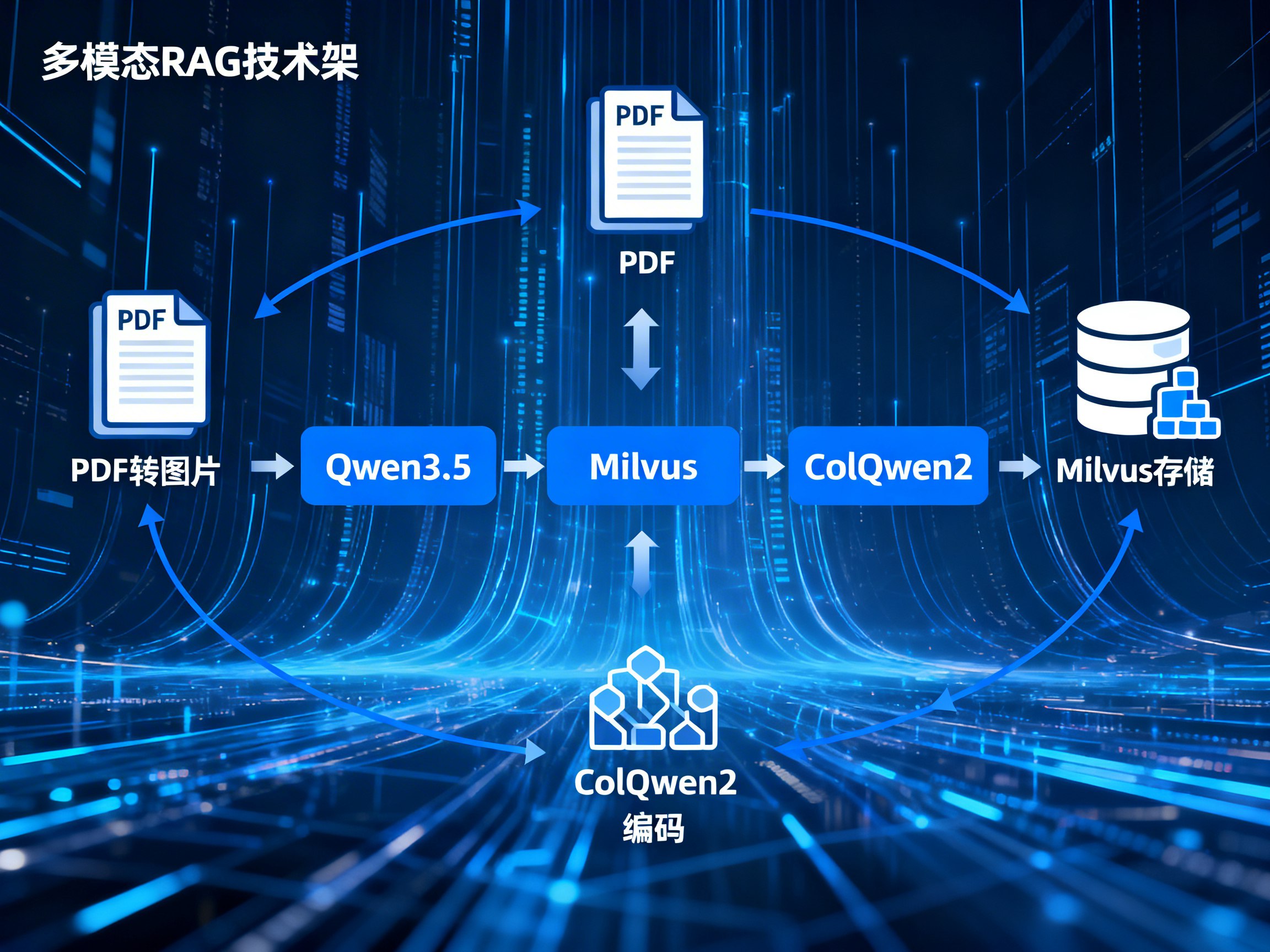
- ColQwen2 的视觉编码能力:作为视觉语言模型,ColQwen2 彻底改变了文档索引的方式。它不再尝试将图片转化为文字,而是将每一页 PDF 渲染为图片,并将其编码为 ColBERT 式的多向量表示。每一页文档会被拆解为数百个 128 维的 Patch 向量,从而保留了排版、手写批注、表格线条等所有视觉细节。
为什么选择多模态 RAG?
相比于传统 RAG,多模态 RAG 的优势是颠覆性的。在 AI 新闻 频繁报道的各类应用场景中,多模态方案正逐渐成为主流。
- 信息零损耗:由于跳过了 OCR 步骤,文档中的表格、数学公式、流程图等视觉信息被 100% 保留。
- 精准的局部匹配:通过 ColBERT 的多向量检索逻辑,系统可以实现“Token 对 Patch”的精细匹配。这意味着即便问题涉及文档角落里的一个小备注,系统也能精准定位。
- 极简的处理流程:无需复杂的文本清洗、分词或复杂的解析逻辑,直接将 PDF 转图片即可入库。
技术栈与实操指南:从环境准备到检索实现
要构建这套系统,我们需要整合以下核心组件:ColQwen2(负责向量化)、Milvus(负责高性能向量存储与检索)以及 Qwen3.5(负责最终的生成回答)。
1. 环境准备与模型加载
2. 初始化 Milvus 向量数据库
3. PDF 编码与入库
4. 核心检索逻辑:MaxSim 算法
视觉生成:Qwen3.5 的“读图”能力
在检索到最相关的 PDF 页面后,系统不会提取文本,而是直接将这些原始图片连同用户的问题一起发送给 Qwen3.5。
借助 Qwen3.5 强大的多模态理解能力,它能够像人类一样“看”着图片进行分析。无论是对比两份财报中的数据差异,还是解释流程图中的逻辑步骤,Qwen3.5 都能给出简洁、准确且极具上下文感知力的回答。这种“所见即所得”的问答体验,是传统文本 RAG 无法企及的。
总结与展望
基于 Qwen3.5+Milvus+ColQwen2 的多模态 RAG 方案,为企业知识库、论文检索及复杂文档分析提供了一套高精度的标准解法。虽然图片编码在计算资源上比纯文本略有增加,但其带来的检索精度提升和对复杂格式的兼容性,使其在 AGI 时代具有极高的应用价值。
如果你希望了解更多关于 大模型 应用、提示词工程(Prompt)以及 AI 变现的深度内容,请持续关注我们。多模态 RAG 不仅仅是技术的升级,更是我们与海量文档交互方式的一次质变。
Loading...