.png?table=collection&id=cbe6506e-1263-8358-a4d7-07ce62fcbb3f&t=cbe6506e-1263-8358-a4d7-07ce62fcbb3f)
TPAMI重磅:DC-SAM打破交互限制,实现高效视频上下文分割
type
status
date
slug
summary
tags
category
icon
password
网址
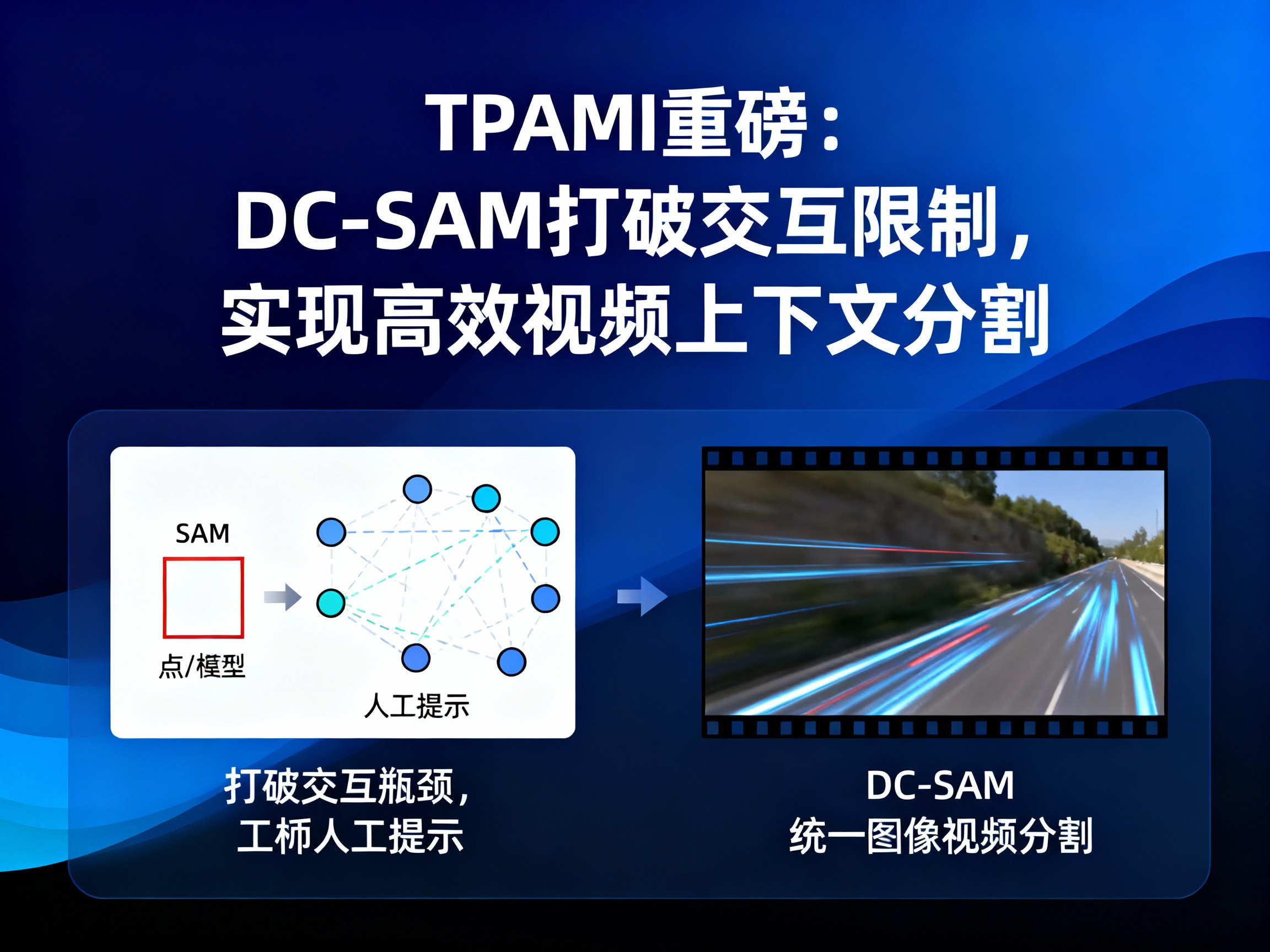
在当今人工智能飞速发展的时代,视觉基础模型(Vision Foundation Models)如SAM(Segment Anything Model)和SAM2凭借其卓越的零样本泛化能力,已成为计算机视觉领域的里程碑。然而,尽管这些大模型在“分割一切”的任务上表现出色,但在实际应用中仍面临一个显著的交互瓶颈:它们通常依赖于繁琐的人工提示(如点或框)来指定目标。这种交互方式不仅限制了批量处理的自动化效率,更使得模型在处理复杂的连续视频流时,难以维持时空的一致性。
针对这一挑战,北京邮电大学联合南洋理工大学等顶尖科研机构,在IEEE TPAMI期刊上发表了题为《DC-SAM: In-Context Segment Anything in Images and Videos via Dual Consistency》的重磅论文。该研究不仅提出了一种基于循环一致性的新框架DC-SAM,还构建了首个视频上下文分割基准IC-VOS。本文将深入解读这一打破SAM交互限制的创新技术,探讨其如何为AI资讯领域带来新的技术风向。欲了解更多前沿AI新闻和AGI动态,请访问 AINEWS。
上下文分割的痛点与DC-SAM的突破
所谓的“上下文分割”(In-Context Segmentation),是指模型仅凭一张参考示例(Support Image)及其对应的掩码,就能自动在查询图像(Query Image)中识别并分割出同类目标的能力。这类似于自然语言处理中的提示词(Prompt)工程,但在视觉领域实现起来难度极大。
现有的解决方案要么依赖计算资源消耗巨大的通用模型(如SegGPT),要么是简单的提示微调方法,后者往往忽略了SAM自身提示编码器的特性,且未能充分利用背景(负样本)信息。DC-SAM的出现正是为了解决这一痛点。它巧妙地利用了SAM与SAM2的架构一致性,通过引入“循环一致性”机制,实现了图像与视频任务的统一高效适配,无需昂贵的重新训练,即可让SAM具备强大的上下文理解能力。
核心技术:正负双分支循环一致性
DC-SAM的核心创新在于其“正负双分支循环一致性提示生成”模块。传统的微调方法容易产生边界模糊或语义漂移的问题,即模型可能会错误地匹配非目标区域。
为了解决这个问题,研究团队设计了双分支结构:
1. 正分支:专注于捕捉目标的前景特征。
2. 负分支:专门用于识别和抑制背景干扰。
更为精妙的是,为了防止AI在特征匹配时产生幻觉,团队引入了“循环一致性交叉注意力”(Cyclic Consistent Cross-Attention)。该机制就像一个严格的校验官,只有当支持图像中的像素与查询图像中的匹配像素在语义类别上高度一致时,才保留注意力权重;否则,通过偏置项将其屏蔽。这种机制确保了生成的Prompt仅聚合高度可信的特征,极大地提升了分割的精准度。
视频领域的创新:Mask-tube训练策略
如果说图像分割是静态的挑战,那么视频分割则是对时空一致性的终极考验。在此之前,视频领域的上下文分割研究几乎处于空白阶段。现有的基准主要侧重于半监督跟踪,而非基于参考示例的自动分割。
DC-SAM通过设计轻量级的Mask-tube(掩码管道)训练策略,成功将SAM的能力迁移至视频领域。该策略通过数据增强将静态图像堆叠为伪视频序列,模拟连续帧之间的时序变化。配合大模型SAM2的架构优势,DC-SAM能够处理极小目标分割、快速运动变形以及复杂背景融合等极端场景,有效抑制了视频传播过程中的语义漂移现象。
填补空白:首个视频上下文分割基准IC-VOS
除了算法上的创新,该研究对人工智能社区的另一大贡献是推出了IC-VOS (In-Context Video Object Segmentation) 数据集。这是首个专门用于评估模型在视频上下文中学习能力的基准。
现有的数据集往往丢失了时间维度或仅关注第一帧掩码追踪,而IC-VOS涵盖了丰富的场景,旨在全面衡量模型“基于参考示例进行视频分割”的能力。这一基准的建立,为未来LLM和视觉模型的融合研究提供了标准化的测试平台,有助于推动AI变现在视频编辑、自动驾驶等领域的落地。
实验结果与SOTA性能表现
实验数据有力地证明了DC-SAM的优越性。在图像上下文分割基准COCO-20i上,DC-SAM达到了55.5 mIoU,而在Pascal-5i上更是高达73.0 mIoU。值得注意的是,即使面对使用了海量图文对训练的通用模型SegGPT,基于DINOv2的DC-SAM依然实现了近6%的性能反超。
在新建的IC-VOS视频基准上,DC-SAM取得了71.52的J&F得分,显著优于现有的VRP-SAM和PerSAM等方法。可视化结果显示,无论是在处理复杂的“自行车”结构,还是在追踪快速移动的“摩托车”时,DC-SAM都能生成边缘清晰、语义稳定的掩码,展现了SOTA(State-of-the-Art)级别的性能。
总结
DC-SAM的提出,不仅解决了SAM在自动化交互上的短板,更通过统一的框架打通了图像与视频的上下文分割任务。对于关注AI日报和技术落地的开发者而言,这意味着在工业质检、医疗影像分析以及视频内容创作等领域,将拥有更高效、更自动化的解决方案。随着人工智能技术的不断演进,类似DC-SAM这样结合了基础模型优势与创新微调策略的方法,必将成为未来AGI发展的重要推动力。
更多关于大模型、ChatGPT及Claude等前沿技术的深度报道和资源,欢迎访问 AINEWS 获取最新资讯。
Loading...